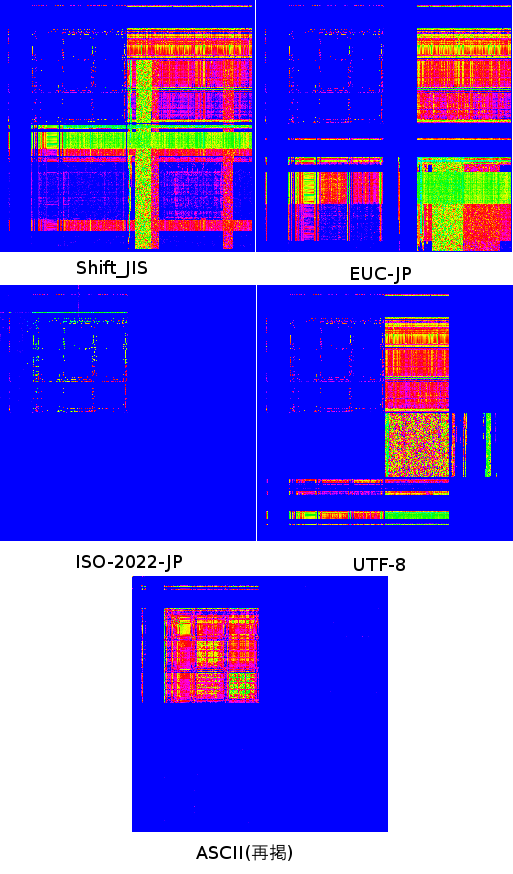
以下の記事の続きです。最終編~♪
■abstract
@nebutalabさんの追試結果を踏まえて、私もベクトルデータの解像度を下げる効果について検討しました。その上で、既存のライブラリ(Webkit/Chromeに組み込まれているライブラリ)と比較を行いました。
さらにベクトルデータをlogを用いて圧縮する方法を検討したところ、既存のライブラリと同程度にまでメモリ消費を下げることができました。
最後の仕上げとして、autotoolsを用いたライブラリとしてまとめて公開しました。
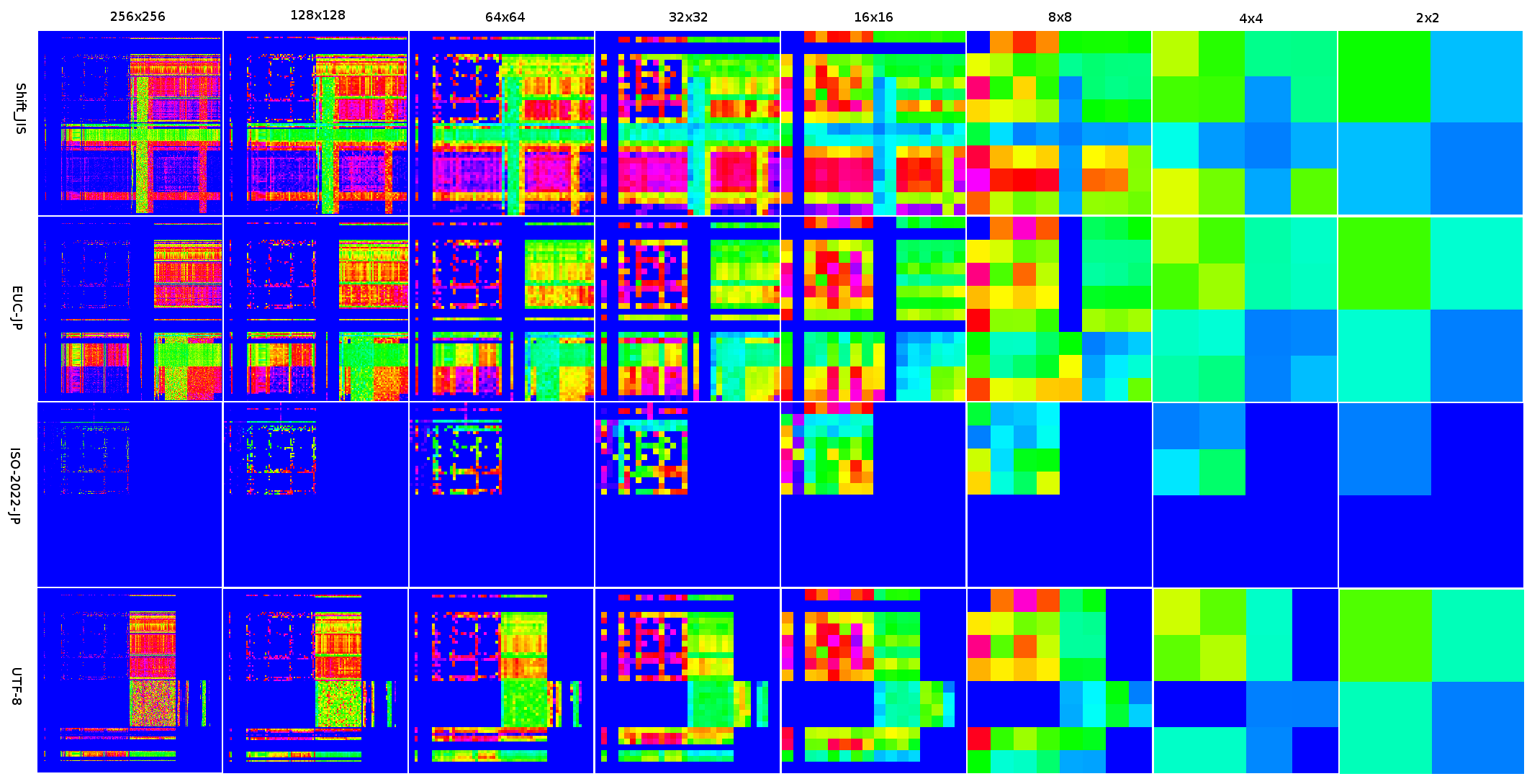
■解像度を下げてもなお特徴的なベクトルデータ
@nebutalabさんのエントリでは、二次元でなく一次元での推定テストを行った他、二次元の場合に、ベクトルデータの解像度を下げてどれくらい推定成功率が下がってしまうかのテストを行っていらっしゃいます。
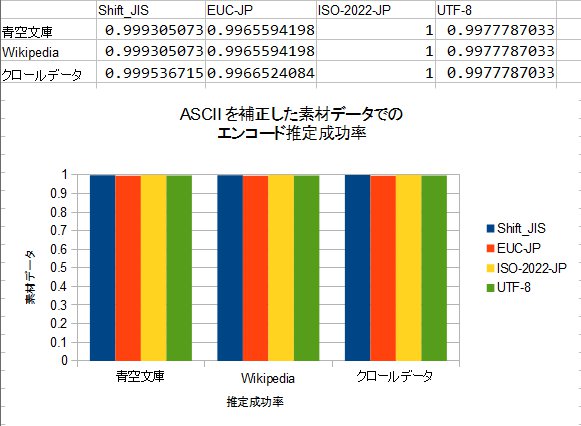
なぜ、解像度をさげて正確性を犠牲にしてまで、ベクトルデータのサイズを小さくしなくてはいけないのでしょう?元のままだと、ベクトルデータが各エンコードごとに256×256=65536要素必要で、uint32(4バイト)で持っていると256KBも必要になってしまいます。Shift_JIS、EUC-JP、ISO-2022-JP、UTF8と4種類用意するとトータルで1MBです。実際に使おうとするとこのメモリ消費量の大きさがネックになってしまい、ソフトウェアの一部として組み込むには使いづらいからです。
とりあえず、私の側でも解像度を下げたデータを作って見ました。
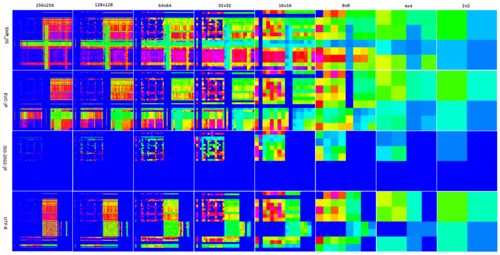
うーん、16×16までは確実に差が分かるけど、8×8くらいから怪しいかなあ、といった感じでしょうか。
■解像度を下げて実験!
今回は、@nebutalabさんの方法を参考に、ページ内でcharsetを指定してあるページのみをテスト用デ-タに使うことで、ノイズを排除しました。あと、方式は前回検討し疑似コードでの方式をベースに、charCntはどれかの文字コードのスコアが0より大きい物(判定として使える物)にしました。解像度を下げていくと、これは最初の擬似コードの方式と殆ど同じになります。
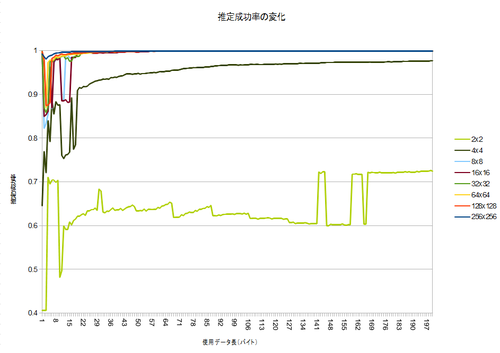
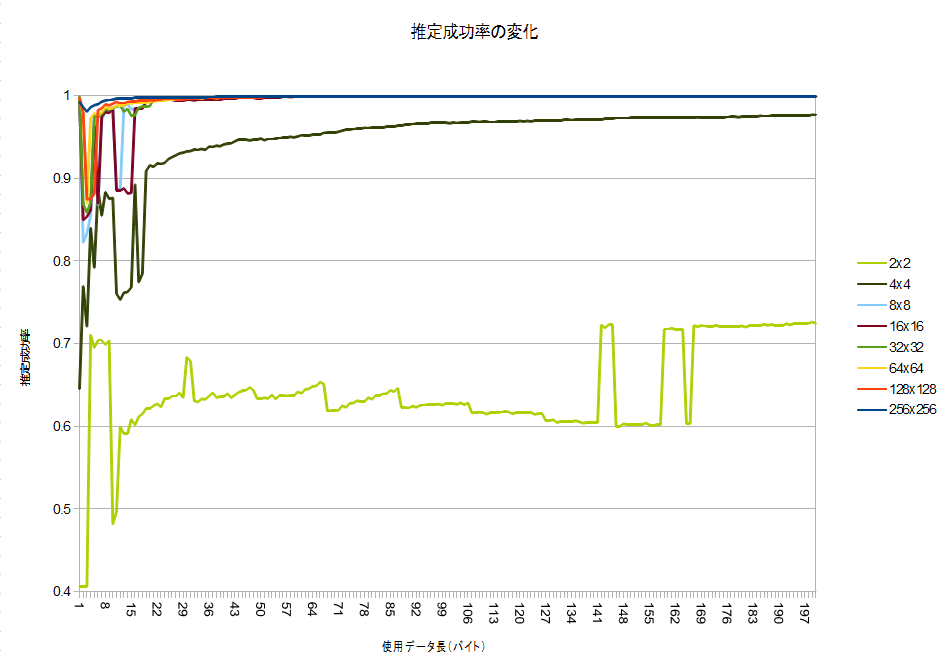
意外にも8×8では十分判定(100バイト時点で99.907%)でき、4×4で怪しくなってきて、2×2では全然だめ、という感じのようです。それでも、Random guess(25%)よりは高く、7割程度分かってしまうようです。…確率って凄いですね。
@nebutalabさんのものよりも成績が良いのは、おそらくやっぱり辞書データのサイズの差だと思われます。Wikipedia全文データはやはり広大みたいです…。
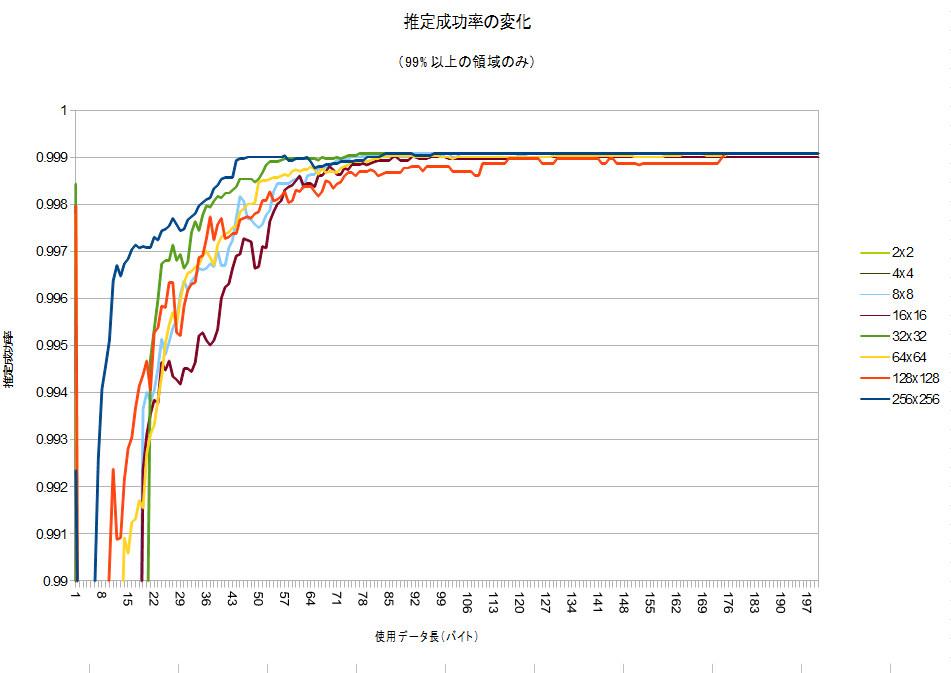
99%以上の部分についてのみのグラフがこちらです。

128×128で何故か収束が悪いですが、おおむね100バイト収集すれば収束するようです。ちょっと面白いのが、1バイトだけ使った方が、その後の50バイト分よりも判定率が良いこと!99.8%の精度が出ているので、案外これで十分!?かもしれません^^;
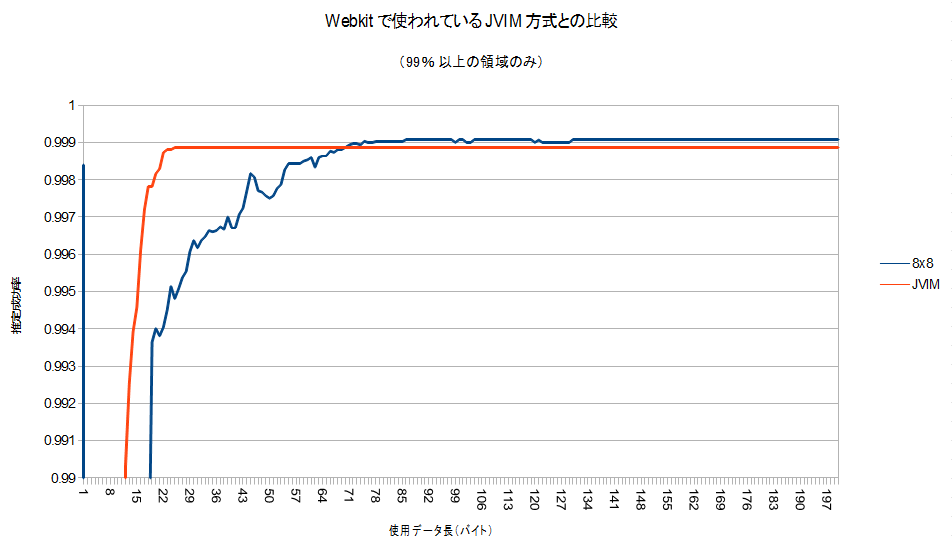
■webkitのコードと比較してみる
Chrome/Webkitで、HTTPのレスポンスヘッダやmeta要素でのcharsetと、テキストの実際のエンコードが食い違った時に推定するために使われる、TextResourceDecoder::detectJapaneseEncoding(const char* data, size_t len)と、性能を比較しました。コメントから、このコードは、JVIM由来だそうです。具体的に実装を見るとわかりますが、このコードもヒューリスティックなアルゴリズムですが、それぞれの文字コードへの深い知識を使って実装されており、今回のアルゴリズムとは対照的といえます。
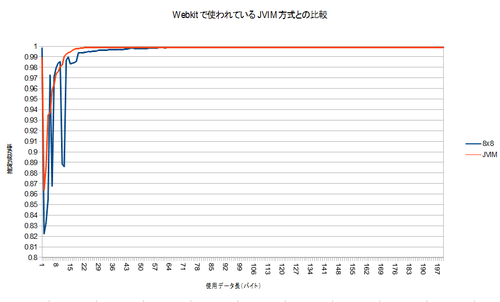
どちらのコードも、最初の1バイトで高い性能を示し、いったんガクっと落ちる点など、非常によく似た性質を示しています。8×8の辞書サイズでは最初の方のデータのグラフが安定しませんが、おおむね同じような収束曲線を示しているように見えます(私の贔屓かな…)。なお、JVIMの実装はShift_JIS/EUC-JP/ISO-2022-JPの三種類しか判定できないので、そういう意味では私の勝ちです(ぇ
こちらも99%以上の部分を拡大したものがこちらです。

100バイト使うことが出来れば、わずかにですが、このwebkitのコードより良い性能を示しています。(合計で22876件のテストデ-タを使いました。誰か検定してください(えー))
実行時間の殆どはIOなので実行速度は問題にならないと思いますが、webkitのコードよりも確実にコード量は少なく(=省メモリ)て済んでいます。
■さらに、Logを使って圧縮しよう。
8×8にまでベクトルサイズを下げることで、ベクトルの要素を32bitのfloatで持つと、8x8x4(bytes)*4(種類のエンコード)=1024バイトにまでベクトルデータを削減することが可能ですが、これでもwebkitの実装の256バイトよりはだいぶ大きくなってしまいます。できれば、同等のメモリ消費量程度にしたいですよね。
もし、各ベクトルの要素を1バイトで表現するようにデ-タを圧縮する事ができれば、webkitの実装と同じ、256byte前後でベクトルデ-タが収まります。圧縮すると、展開のために少し速度が遅くなると思われますが、処理速度の大半はIOな上に、アルゴリズムは現状非常にシンプルなので、多少遅くなっても問題無いでしょう。
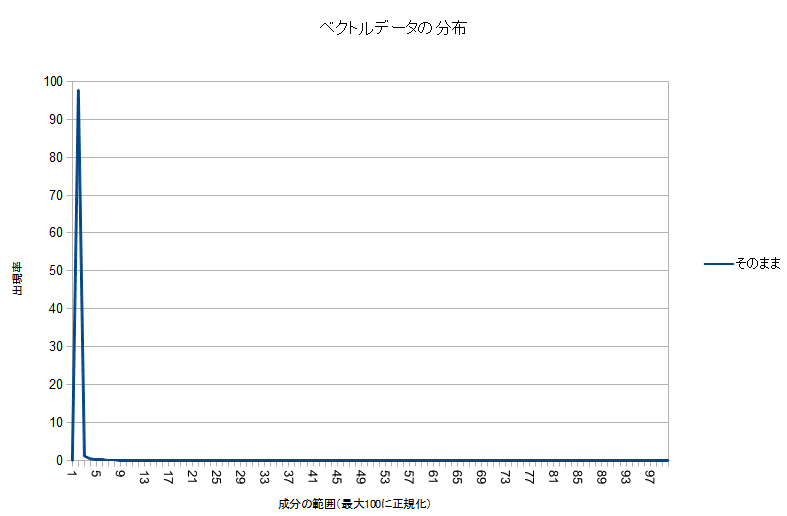
まず、データの分布を見て、特性を観察しましょう。ベクトルの要素のうち、最大のものを100%として、0~1%の間の大きさの要素が何要素あるか、1~2%の間の大きさの要素が何要素があるか…という、ヒストグラムを作ってみました。

!?…どうやら、殆どのベクトル要素は、非常に小さい部分に集中しているようです。
となると、もし、ベクトルの要素の最大値を255とした場合に、各要素がどれくらいの割合か、でデ-タを表すことで圧縮してしまうと、圧縮後の要素が0~2の要素ばっかりのベクトルになってしまい、なんだかもったいないデ-タの使い方になってしまいます。また、解凍して元の要素を復元したときに、元々色々な値を持っていたはずの、値が小さい範囲の要素が、みんな同じ値に復元されてしまうことになります。
デ-タの使い方がもったいない上に、精度も悪い圧縮になってしまうので、これでは圧縮としては使えません。
では、どういう風に圧縮しましょう?小さい要素の差がつぶれて、みんな同じ値になってしまうと、もしテストデ-タを比較するときに、小さいベクトル要素ばかりが出現した場合に、みんな同じ値になってしまうので比較できなくなってしまうだろう、と思われます。逆に、非常に大きい値は、他を圧倒しているため、多少ズレてしまっても文字コ-ド別に順位を取った際の順番はあまり変わらないだろう、と考えられます。もしも圧縮するなら、小さい値をできるだけ正確に保存して、大きい値は割と目をつぶる…そんな感じが良いでしょう。
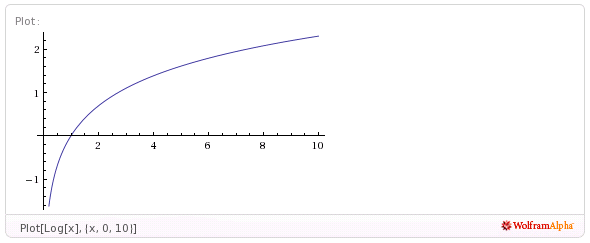
小さい要素の値をできるだけ正確に表しつつ、大きい要素はあまり正確でなくてもいい…そこで使うのが、Logです!

Wolfram Alpha先生に書いてもらった図です。便利ですね~。Log(x)は、xが小さい範囲では急激に増加しますが、大きくなってくると増加が緩やかになります。この関数を通すことで、値の小さい範囲の差を拡大し、大きい範囲では逆に縮小する事ができるのです。
さてさて。というわけで、ベクトルの各要素にLogを取った後に同じようにプロットした結果がこちら。
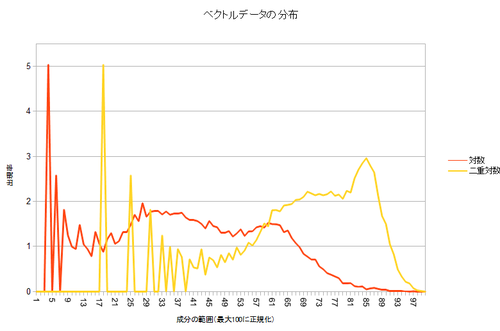
どうでしょう?だいぶ、グラフ上の色々なところに値が出現するようになりましたよね。Logを取った結果に、さらにLogを取るという二重対数というのもやってみましたが、これもそれなりに良い感じです。これを、最大値を255、最小値を0として表して、ベクトルデ-タを圧縮しました。
圧縮したデ-タを、再度元に戻した場合に、元のデ-タからどれくらい”ズレ”てしまってるかを計りました。具体的には、復元後のベクトルデ-タの各要素の合計を、元デ-タの各要素の合計で割りました。
- 何もしない(ただ最大値=255として1バイトで表す)
- Shift_JIS: 99.1276634489251%
- EUC: 98.3539033976696%
- ISO-2022-JP: 99.2222804703025%
- UTF-8: 98.8167690319413%
- 対数
- Shift_JIS: 0.392150481159483%
- EUC: 0.823989278166709%
- ISO-2022-JP: 0.419194323315878%
- UTF-8: 0.541541587104492%
- 二回対数
- Shift_JIS: 0.415910841860486%
- EUC: 0.77325609663897%
- ISO-2022-JP: 0.249110000167609%
- UTF-8: 0.574984371330254%
やっぱり何もしないのでは全然駄目でしたが、対数を使うととても正確で、二回対数にするとさらに少し改善するみたいです。どちらにしてもでも1%以下しか変わらないため、きっと良い結果が得られると考えられます。
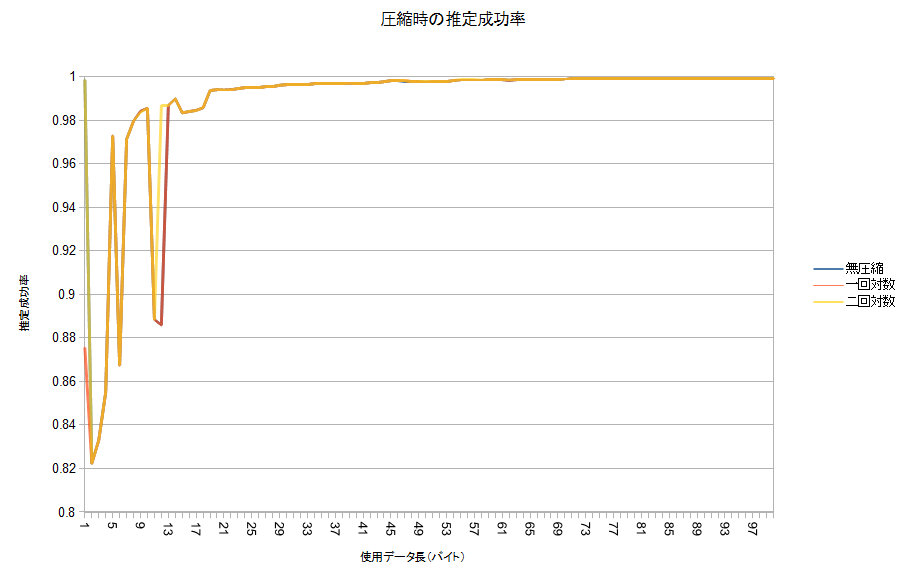
■webkitと同程度のメモリ消費に抑えても、同じ程度の性能が出る
その結果がこちら。

どうでしょう?一回対数の場合、1バイトだけ使ったときの推定成功率は大きく下がりましたが、元のグラフから殆ど外れないグラフが書けました。100バイト使った時の成功率は、元の結果と全く同じ。デ-タを1/4に圧縮しましたが、副作用はありませんでした。
二回対数は正直かなり重いので、実装するには一回対数を使って圧縮すると良さそうです。
■C言語のライブラリとして実装しよう!&autotoolsの使い方
githubで公開中!
さてさてさてて。すべての条件がそろいました。十分な判定率と十分なメモリ消費量、それでもシンプルなアルゴリズムを用意できました。ならば、これをライブラリにしない手は、ありませんよね!?
とてもシンプルなライブラリですから、せっかくなので、autotoolsの使い方も調べてみましょう。一度は自分で./configure & make & make installなパッケ-ジ作ってみたいですよね!ね!!(
とりあえず、こんな構成でコードを書きました。(完成品のソース見ながらの方が分かりやすいと思います)
- include
- src
- data.h
- data.c
- csetguess.c
include以下が/usr/includeとかに入れるためのヘッダで、
enum CSET_GUESS_CHARSETS {
UNKNWON=-1,
SJIS=0,
Shift_JIS=0,
EUC=1,
EUC_JP=1,
JIS=2,
ISO_2022_JP=2,
UTF8=3,
};
enum CSET_GUESS_CHARSETS cset_guess(const unsigned char* data, unsigned int len);
こんな感じのシグネチャが入っています。src以下はその具体的な実装です。cset_guessはcsetguess.cに入っています。
さて。これからautotoolsを使って、ビルド環境を作りましょう。autotoolsは、仕様が頻繁に変わってしまうのか、公式のドキュメントを見ても、なんかよく分かりません…。一応、作業の流れはWikipediaの図が参考になりました。Googleで検索するときも、できるだけ最新の情報を見るのをお勧めします…。
まず、トップディレクトリにMakefile.amを、こんな感じで作ります。
lib_LTLIBRARIES = libcsetguess.la
libcsetguess_la_SOURCES= \
src/data.h \
src/data.c \
src/csetguess.c \
include/csetguess.h
includedir=$(prefix)/include
include_HEADERS=include/csetguess.h
次に、autoscanをして、configure.scanをつくり、これをconfigure.acにリネームします。
$ autoscan
$ mv configure.scan configure.ac
configure.acのうち、
AC_INIT([FULL-PACKAGE-NAME], [VERSION], [BUG-REPORT-ADDRESS])
となってるところを、とりあえず自分のものに併せて変更しました。
AC_INIT([libcsetguess], [1.0], [nasda60@hotmail.com])
Wikipedaの図にそって、aclocal、autoheader、automakeします。このとき、READMEやNEWS、CHANGELOGといったファイルが無いので、automakeするときに作って貰えるように、-a -cというオプションを付けます。
$ aclocal
$ autoheader
$ automake -a -c
configure.ac: no proper invocation of AM_INIT_AUTOMAKE was found.
configure.ac: You should verify that configure.ac invokes AM_INIT_AUTOMAKE,
configure.ac: that aclocal.m4 is present in the top-level directory,
configure.ac: and that aclocal.m4 was recently regenerated (using aclocal).
Makefile.am: installing `./INSTALL'
Makefile.am: required file `./NEWS' not found
Makefile.am: required file `./README' not found
Makefile.am: required file `./AUTHORS' not found
Makefile.am: required file `./ChangeLog' not found
Makefile.am: installing `./COPYING' using GNU General Public License v3 file
Makefile.am: Consider adding the COPYING file to the version control system
Makefile.am: for your code, to avoid questions about which license your project uses.
configure.ac:7: required file `config.h.in' not found
Makefile.am:3: Libtool library used but `LIBTOOL' is undefined
Makefile.am:3: The usual way to define `LIBTOOL' is to add `AC_PROG_LIBTOOL'
Makefile.am:3: to `configure.ac' and run `aclocal' and `autoconf' again.
Makefile.am:3: If `AC_PROG_LIBTOOL' is in `configure.ac', make sure
Makefile.am:3: its definition is in aclocal's search path.
Makefile.am: installing `./depcomp'
/usr/share/automake-1.11/am/depend2.am: am__fastdepCC does not appear in AM_CONDITIONAL
/usr/share/automake-1.11/am/depend2.am: The usual way to define `am__fastdepCC' is to add `AC_PROG_CC'
/usr/share/automake-1.11/am/depend2.am: to `configure.ac' and run `aclocal' and `autoconf' again.
/usr/share/automake-1.11/am/depend2.am: AMDEP does not appear in AM_CONDITIONAL
/usr/share/automake-1.11/am/depend2.am: The usual way to define `AMDEP' is to add one of the compiler tests
/usr/share/automake-1.11/am/depend2.am: AC_PROG_CC, AC_PROG_CXX, AC_PROG_CXX, AC_PROG_OBJC,
/usr/share/automake-1.11/am/depend2.am: AM_PROG_AS, AM_PROG_GCJ, AM_PROG_UPC
/usr/share/automake-1.11/am/depend2.am: to `configure.ac' and run `aclocal' and `autoconf' again.
た、たくさんエラーメッセージが出てしまいましたが、これらを地道に修正します。
@@ -2,12 +2,15 @@
# Process this file with autoconf to produce a configure script.
AC_PREREQ([2.67])
AC_INIT([libcsetguess], [1.0], [nasda60@hotmail.com])
+AM_INIT_AUTOMAKE([foreign])
AC_CONFIG_SRCDIR([include/csetguess.h])
AC_CONFIG_HEADERS([config.h])
+AC_CONFIG_MACRO_DIR([m4])
# Checks for programs.
AC_PROG_CC
+AC_PROG_LIBTOOL
# Checks for libraries.
AM_INIT_AUTOMAKEの引数がよく分からないのですが、とりあえずこれで良いみたいです(そもそもこのAM_INIT_AUTOMAKEの解説、古いのでは…?よくわかりません…)。
さて、修正したところで、再度aclocalから行って行きます。
$ aclocal
$ autoheader
$ automake -a -c
configure.ac:13: installing `./config.guess'
configure.ac:13: installing `./config.sub'
configure.ac:6: installing `./install-sh'
configure.ac:13: required file `./ltmain.sh' not found
configure.ac:6: installing `./missing'
”configure.ac:13: required file `./ltmain.sh’ not found”するには…最初libtoolizeというのをしなければならなかったようです(Wikipediaに書いてないぞ~)
$ libtoolize
libtoolize: putting auxiliary files in `.'.
libtoolize: linking file `./ltmain.sh'
libtoolize: putting macros in AC_CONFIG_MACRO_DIR, `m4'.
libtoolize: linking file `m4/libtool.m4'
libtoolize: linking file `m4/ltoptions.m4'
libtoolize: linking file `m4/ltsugar.m4'
libtoolize: linking file `m4/ltversion.m4'
libtoolize: linking file `m4/lt~obsolete.m4'
$ automake -a -c
うまく行きました。さて最後にautoconfすることで、ついにあのconfigureスクリプトが生成されます。
$ autoconf
さて、これでconfigureしましょう。
$ ./configure
....
configure: creating ./config.status
config.status: creating Makefile
config.status: creating config.h
config.status: executing depfiles commands
config.status: executing libtool commands
おおお!!これで、make & make installができるようになります。
以上をまとめると、
- Makefile.amを書く
- autoscanして、configure.scanを生成し、configure.acにリネームして、編集する。
- 以下のコマンドを実行していく。
- libtoolize
- aclocal
- autoheader
- automake -a -c
- autoconf
- ./configureスクリプトができて、晴れて完成。
こんな感じです。はしょりまくりですが、とりあえずの雰囲気掴みには…なってると良いな…。とりあえず、Makefile.amとconfigure.acさえあれば全部自動生成されるので、この二つ以外はリポジトリに入れなくても大丈夫です。
■ブラウザに実装しないの?
技術的障壁が二つほど横たわっております。
- Chrome/Firefoxともに、拡張機能からページのエンコ-ド設定を変更する方法が見当たらない
- ペ-ジのテキストを、拡張機能からバイナリとして取得する方法が見つからない
後者は、Ajax的にリクエストを投げて、その結果をバイナリとして受け取る事でできそうなのですが、わざわざ再度リクエストを投げるのは計算機資源の無駄だと思います…。前者はセキュリティ的問題でしょうか…?
さらに、ブラウザ本体に組み込むというのも考えたのですが、このパソコンではどうやらメモリ不足みたいで、コンパイルに時間がかかりすぎて、デバッグや開発がどうにも不可能そうです…orz
解決方法をご存知の方がいらしたら、教えてください!
■まだちょっとやり残した気がすること
今回のJVIM由来のwebkit内のライブラリは、実はいつも使われるわけでなく、HTTPヘッダやmetaタグで指定したエンコードと実際のエンコードが食い違っている場合にのみ使われます。
そして、一切無指定だった場合はICUというUnicodeのライブラリを使ってエンコードの推定を行っています。
このICUもずいぶん高性能なライブラリのようなのですが、どうしてChrome/Webkit/Safariは文字化けが起きがちなのか、デバッグして調べたかったのです…が…。PCのメモリがどうも足りないみたいで、出来ませんでした。悲しい。