ここにある不具合そのものに突き当たりました。コメントだとPython 3.10じゃないからではないかとか、rustcのバージョンが新しいから(!)ダメなのではないか、といった議論があるのですが、Rustに関してはIssueに「解決した」とされるver 1.65.0まで下げても同じエラーでしたし、そもそもコンパイルエラーは casting &T to &mut T is undefined behavior と正当に思えるものですから3、rustのバージョンはそのまま1.82.0のまま動かすことにしました。
# 初期化
% git init
Initialized empty Git repository in C:/Users/kaede/src/t/.git/
# Linusのリポジトリをoriginとして追加
% git remote add origin git@github.com:torvalds/linux.git
# 問題のコミットだけfetch
% git fetch --depth=1 origin 4fbc49920463c394fc2615f00ecc907a2ce943da
remote: Enumerating objects: 3, done.
remote: Counting objects: 100% (3/3), done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 0), reused 3 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), 638 bytes | 70.00 KiB/s, done.
From github.com:torvalds/linux
* branch 4fbc49920463c394fc2615f00ecc907a2ce943da -> FETCH_HEAD
# mainブランチにmerge
% git merge 4fbc49920463c394fc2615f00ecc907a2ce943da
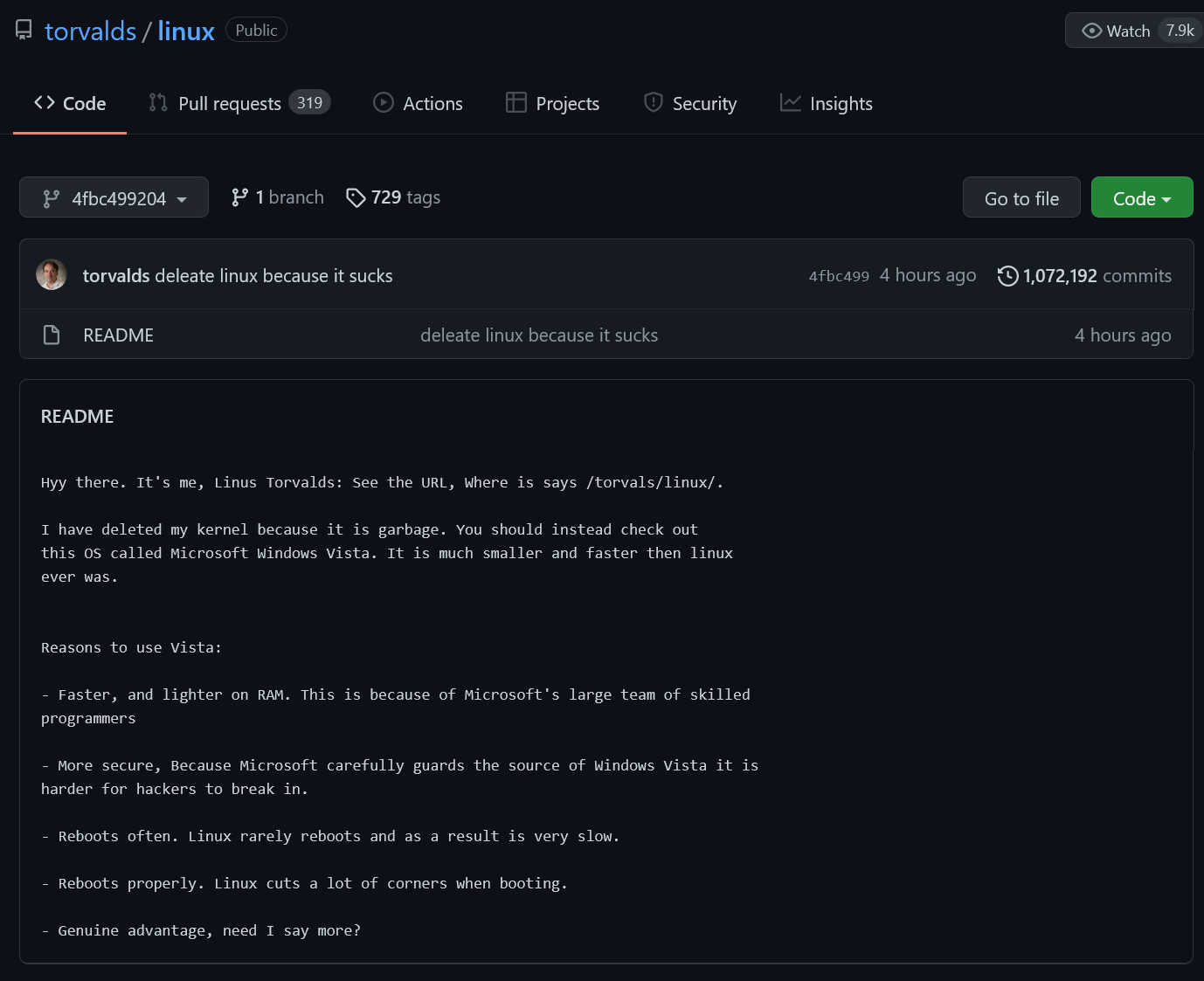
# ファイルを確認すると…
% cat README
Hyy there. It's me, Linus Torvalds: See the URL, Where is says /torvals/linux/.
I have deleted my kernel because it is garbage. You should instead check out
this OS called Microsoft Windows Vista. It is much smaller and faster then linux
ever was.
...
% certbot --help certonly
usage:
certbot certonly [options] [-d DOMAIN] [-d DOMAIN] ...
....
--dns-cloudflare Obtain certificates using a DNS TXT record (if you are using Cloudflare for DNS). (default: False)
--dns-cloudxns Obtain certificates using a DNS TXT record (if you are using CloudXNS for DNS). (default: False)
--dns-digitalocean Obtain certificates using a DNS TXT record (if you are using DigitalOcean for DNS). (default: False)
--dns-dnsimple Obtain certificates using a DNS TXT record (if you are using DNSimple for DNS). (default: False)
--dns-dnsmadeeasy Obtain certificates using a DNS TXT record (if you are using DNS Made Easy for DNS). (default: False)
--dns-gehirn Obtain certificates using a DNS TXT record (if you are using Gehirn Infrastructure Service for DNS). (default: False)
--dns-google Obtain certificates using a DNS TXT record (if you are using Google Cloud DNS). (default: False)
--dns-linode Obtain certificates using a DNS TXT record (if you are using Linode for DNS). (default: False)
--dns-luadns Obtain certificates using a DNS TXT record (if you are using LuaDNS for DNS). (default: False)
--dns-nsone Obtain certificates using a DNS TXT record (if you are using NS1 for DNS). (default: False)
--dns-ovh Obtain certificates using a DNS TXT record (if you are using OVH for DNS). (default: False)
--dns-rfc2136 Obtain certificates using a DNS TXT record (if you are using BIND for DNS). (default: False)
--dns-route53 Obtain certificates using a DNS TXT record (if you are using Route53 for DNS). (default: False)
--dns-sakuracloud Obtain certificates using a DNS TXT record (if you are using Sakura Cloud for DNS). (default: False)
create a 64-entry message schedule array w[0..63] of 32-bit words
(The initial values in w[0..63] don't matter, so many implementations zero them here)
copy chunk into first 16 words w[0..15] of the message schedule array
Extend the first 16 words into the remaining 48 words w[16..63] of the message schedule array:
for i from 16 to 63
s0 := (w[i-15] rightrotate 7) xor (w[i-15] rightrotate 18) xor (w[i-15] rightshift 3)
s1 := (w[i-2] rightrotate 17) xor (w[i-2] rightrotate 19) xor (w[i-2] rightshift 10)
w[i] := w[i-16] + s0 + w[i-7] + s1
Initialize working variables to current hash value:
a := h0
b := h1
c := h2
d := h3
e := h4
f := h5
g := h6
h := h7
Compression function main loop:
for i from 0 to 63
S1 := (e rightrotate 6) xor (e rightrotate 11) xor (e rightrotate 25)
ch := (e and f) xor ((not e) and g)
temp1 := h + S1 + ch + k[i] + w[i]
S0 := (a rightrotate 2) xor (a rightrotate 13) xor (a rightrotate 22)
maj := (a and b) xor (a and c) xor (b and c)
temp2 := S0 + maj
h := g
g := f
f := e
e := d + temp1
d := c
c := b
b := a
a := temp1 + temp2
Add the compressed chunk to the current hash value:
h0 := h0 + a
h1 := h1 + b
h2 := h2 + c
h3 := h3 + d
h4 := h4 + e
h5 := h5 + f
h6 := h6 + g
h7 := h7 + h
Produce the final hash value (big-endian):
digest := hash := h0 append h1 append h2 append h3 append h4 append h5 append h6 append h7