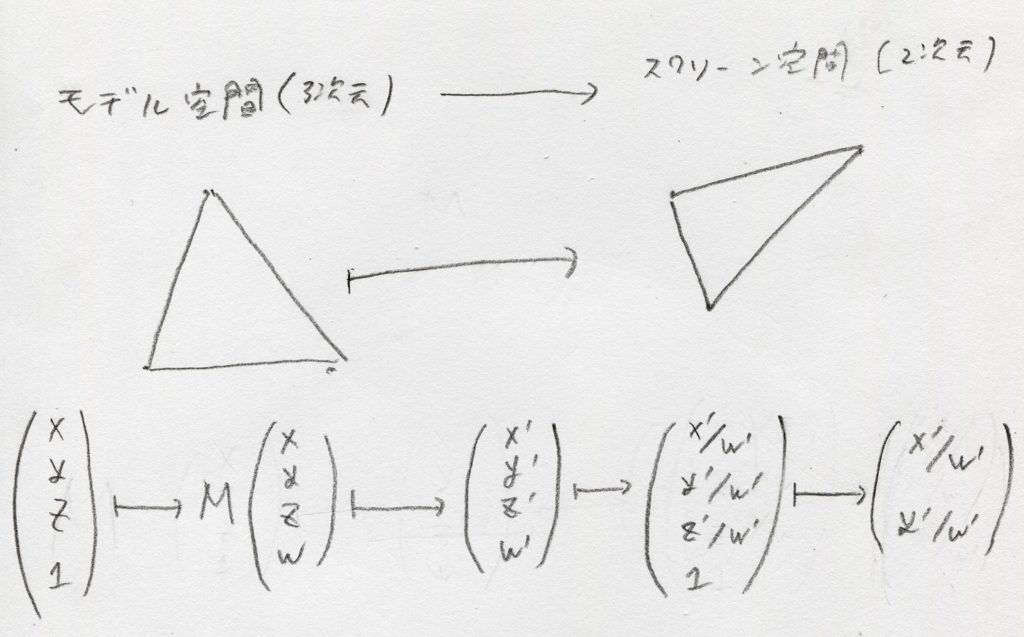
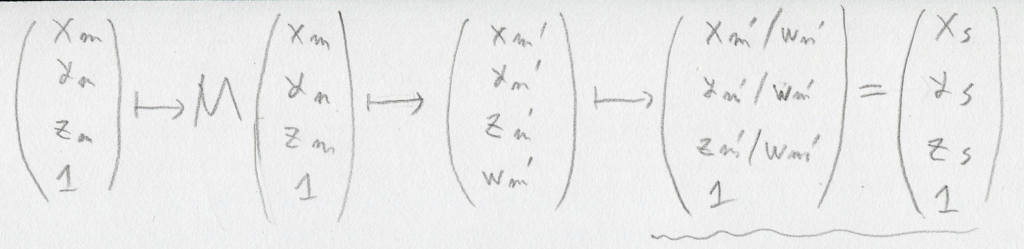
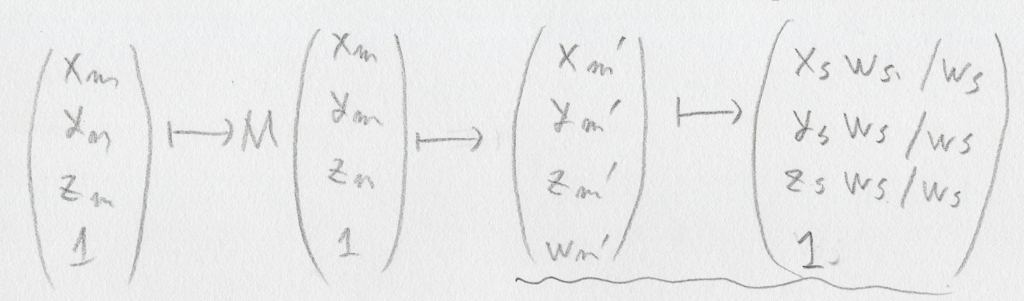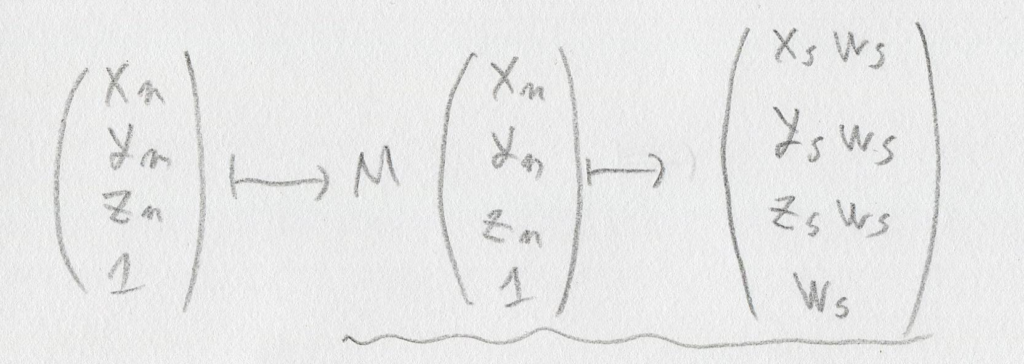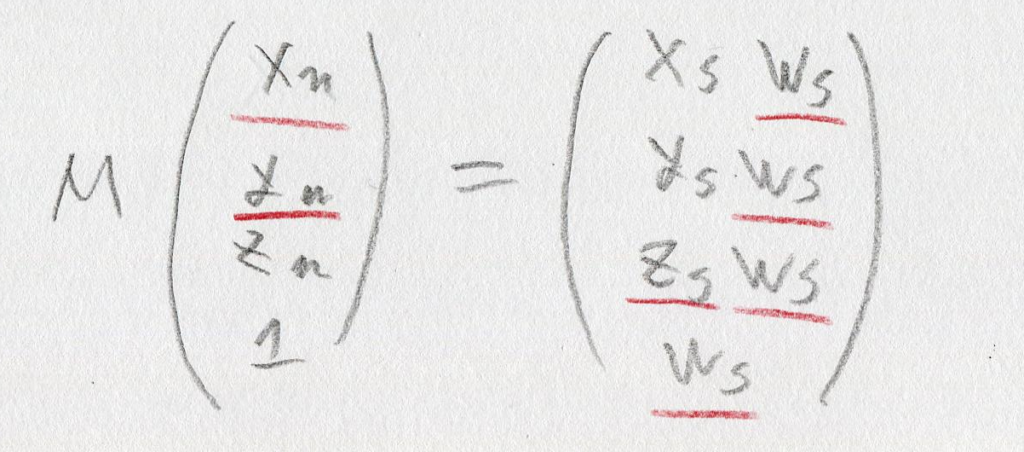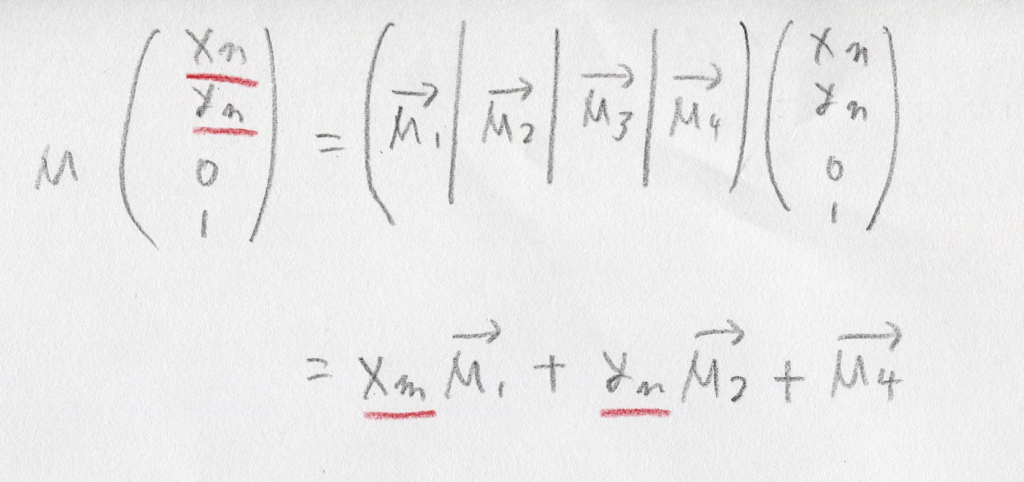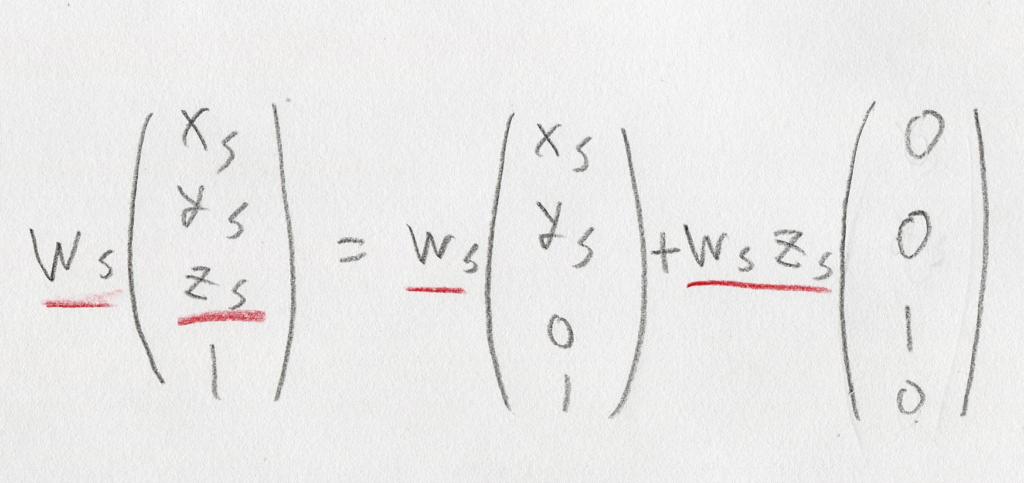引き続きgithubへの「ミラーリング配信」は行います。issueもgithubの方へ書いて頂いて大丈夫です。
Forgejo とは何か
見た方が早いでしょう。githubみたいな、だけど自分のサーバでも動かせる何かです。
公式サイト:Forgejo – Beyond coding. We forge.
(2024/02/10 追記) 翻訳始めました
#74 – [AGREEMENT] ledyba application to the localization team – forgejo/governance – Codeberg.org
翻訳する人がいないなら…もう自分でやるしかないじゃない!あなたも!わたしも!
なぜ移行したのか
まぁ突き詰めると「最近のGithub、なんか『違う』な」ってだけなんですけど、ためしに列挙してみましょう。全部は無理だと思うけど。
倫理観や定義がグローバル基準ではない
サンプル画像として用いている弊サークルのイラスト(複数)が、githubではないものの、海外のイラストサイトから「児童ポルノ」という事で実際にBANされた事がありました。わたしたちは、「児童」も「ポルノ」も、描いてるつもりは、ないのですが…? 小説、レシピ、(作曲した)曲、3Dモデルなど、一般的には「ソフトウェア」とは呼ばれないであろうジャンルのリポジトリもあります。これらすべてについてまで「グローバル基準」な倫理の判定を行われた際に、違反しない自信がありません。以前でしたら「どうせそこまでチェックしてないし、技術的にも資本的にも無理だし、まぁいいか」でしたが、なんでもかんでもTokenにして「AI」と書かれた脳みそのイラストにすべてが放り込まれ、「生産性の向上」「ソフトウェア・サプライチェーンのセキュリティ」なるものがひたすらに叫ばれる昨今、雑に機械で判定されてBANされてしまう危険性は高まっていると感じています。利用規約でも「わいせつ」なものはダメだと書いてあります。その定義をよんでも、わたしには、何が何だか、さっぱり意味が分かりませんでしたが…。
まぁ、わたしのアカウントがBANされるまでなら「バックアップしとけバーカ」で終わるのですが、参照されてしまうと、使っている人も困ってしまいます。オープンソース、ですからね。そんなわけで、弊サーバでホストしつつ、githubへのミラーリングという二段構えの構成をとることとしました。
Githubが寡占しすぎで怖い
なぜ人は寡占をすると付け込まれる事を覚えないのでしょうか。mixiもTwitterも、IE6も、もう忘れたか?
寡占したら次に始まるのは何でしょう?
そう、ロックインですね。まだ逃げ出せる今のうちに、移行しておかなければ、という気持ちになったので、えいやっ!とやりました。
Github Copilot 押しが、あまりにもきな臭く感じる
右上の “Code 55% faster with GitHub Copilot” にご注目ください。
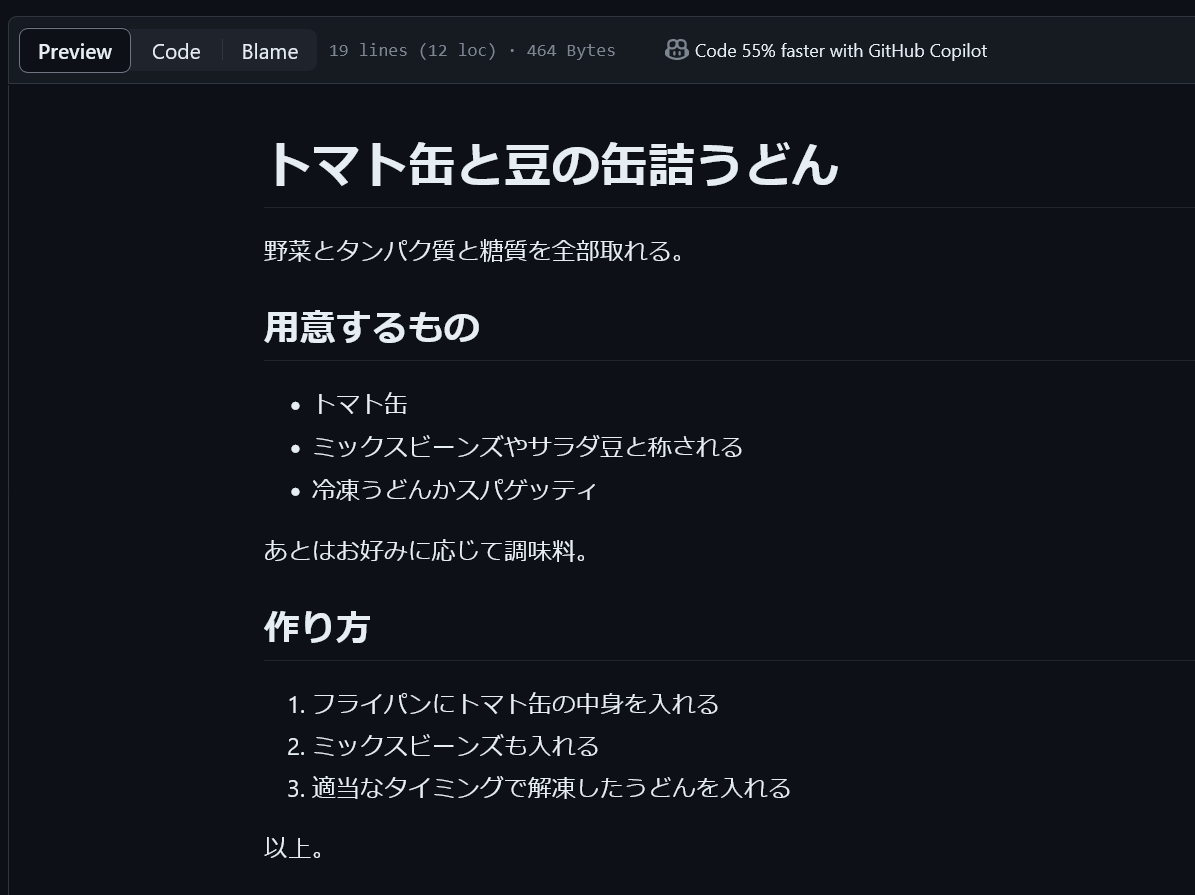
これ料理のレシピですよ?これ55%速くなります?Githubくんは、適当な事を、書いてるだけですよね?Github Copilotくんが料理を作って味見して「おいしい料理のレシピ」を、ぼくの倍速で作ってくれるんですか?
どうも観察すると、Rustだろうが、PHPだろうが、6502のアセンブリだろうが、Cubaseのプロジェクトだろうが、55%速くコーディングできるそうです。
- tiny-ray.rs/src/render.rs at magistra · ledyba/tiny-ray.rs
- kotoba.php/kotoba.php at magistra · ledyba/kotoba.php
- Cycloa/roms/thwaite-0.03/src/cutscripts.s at magistra · ledyba/Cycloa
- cold_rhyme.cubase/cold_rhyme.cpr at magistra · ledyba/cold_rhyme.cubase
アポロ11号のカルマンフィルタの実装も、もちろん、Github Copilot を使えば55%高速に書けるとPRしています。アポロ11号がギリギリ60年代の1969年に着陸して「遅延」したのも、NASAはGithub Copilotへの課金をケチった馬鹿野郎の集まりだからなんでしょうかね?
kotoba.phpには色々な人の、人生に裏打ちされ、丹精に込めて紡がれたであろう、そんな言葉が、たくさん含まれています。これら言葉も、みな、”Code 55% faster with GitHub Copilot” なのだそうです。ほんと、いい加減にしろよ。
これがもしできて、そして、これにお金を出せる酔狂な人は、ぜひ「Copilot Workspace自身」と「仕様を明瞭に記述」したとき、その通りに出力してくれたか教えてください。できたら、あともう料金払わなくてすみますよ。そうじゃなかったら?詐欺だよね?やっぱりもう料金払わなくて、いいよね?
「Git版Fediverse」であるForgefedに期待だ
さて、このforgejo、設定次第ではあるのですが、今建てたインスタンスではユーザー登録は基本的に管理人しかできません。2人ユーザーがいますが、わたしがアカウントを払いだしました。するとgithubのように「ふらっとやってきた人が、不具合を報告していく、直していく」とか、そういう事は基本的にできません。まぁ、それも、ほんとうに、「ごくたまに」しか、発生しないし、いや、でも、昔は掲示板でも置いとけばアカウント登録なんかしなくても不具合の報告ぐらいは、できたんですけどね。そもそもforkボタンなんか押さなくたって、gitコマンドがあればforkはできますし。よくわかんないや。
まぁいいや。しかしながら、たまには誰かが開発に参加してくれたりするのも、事実でございます。
まぁメールでもブログのコメント欄でも、連絡をくれればアカウント作るぐらいはできますよ。実際、それで十分な時もあります。それでも敷居が高い?しょうがないにゃあ・・。いいよ。そんな時の仕組みとして、今頑張って開発されているのがFederation機能、通称ForgeFedです:
プロトコルないし理念:
実装:
- #59 – [FEAT] implement federation – forgejo/forgejo – Codeberg.org
- Support federated pull requests · Issue #184 · go-gitea/gitea
- Federating GitLab through ForgeFed-ActivityPub (#30672) · イシュー · GitLab.org / GitLab · GitLab
短文ブログに比べればかなり機能は多く、実装は難しいものの、歩みも熱量もゼロではありません。技術的にも原理的にも、不可能ではないことも分かり切っています。そのうち、なんとかなるんじゃないかなと思っています。
短文ブログのFederationがはやり始めてから、7年になろうとしています。たしかに「メインストリーム」には、なっていないかもしれませんが、だからこそ、穏やかに続いている。そんな印象です。オープンソースでfederationが出来ても、あるいは出来なくても、そんな感じに落ち着くんじゃないでしょうか。これはわたしの「夢」も半分、なのかもしれませんけどね。
Github”なんか”おっせーよなぁ
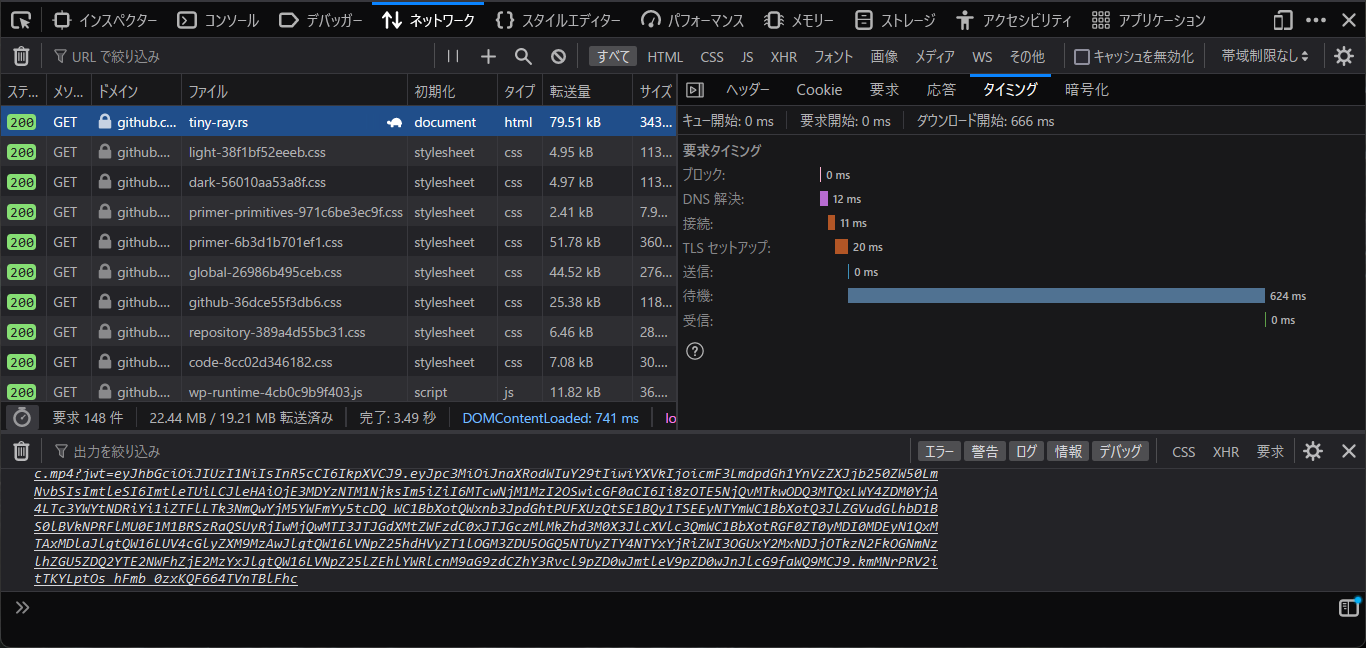
forgejoの方が速いよなぁ:
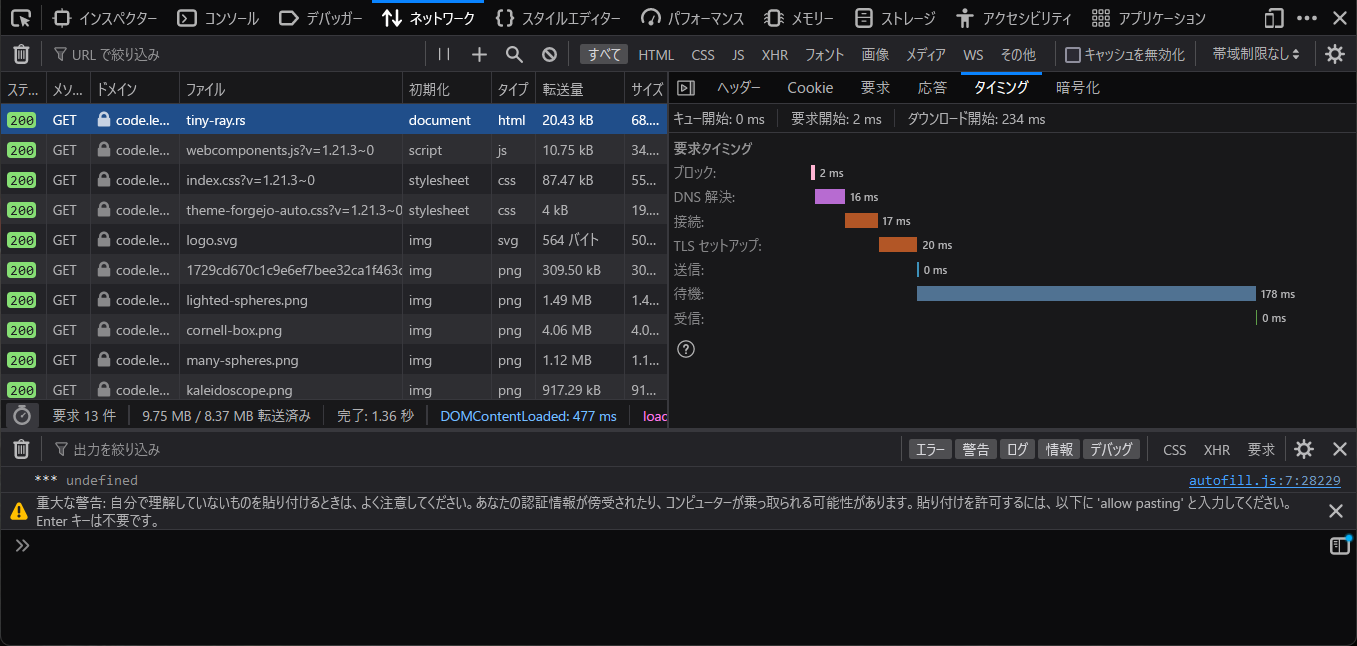
帰ってVPSでforgejo建てようぜ
githubからのbackupには、次のgithubにあるスクリプトを使わせてもらいました:
githubを以てgithubを制す。バイドを以て、バイドを制す!
まぁ一周しただけなんだけどね
昔は同じドメインに建てたSVNサーバ使ってました1:
githubくんはもう忘れちゃったそうですが
「GitHub」で「Subversion」プロトコルのサポートが終了 – 窓の杜
- たぶん自作サーバですね。そのうちVPSも厳しくなってきて、自宅サーバに戻るかもしれません。ただ、いつまで家に公開IPv4/v6アドレスが来るのだろうか…。 [↩]