「AfterCampMeeting 2011」というイベントでのLT。
Yearly Archives: 2011
プログラマのための文字コード技術入門;あなたなら、どう設計して拡張する?
文字コード関連の記事で書いていた「プログラマのための文字コード技術入門」ですが、先日読み終わりました。

プログラマのための文字コード技術入門 (WEB+DB PRESS plus) (WEB+DB PRESS plusシリーズ)
posted with amazlet at 11.12.04
矢野 啓介
技術評論社
売り上げランキング: 36014
技術評論社
売り上げランキング: 36014
はっきり言って凄まじくマニアックな本です。
日本語の文字について、どのような文字が入るかと、文字を区別するための番号を決めてあるJIS X 0208と、それの拡張であるJIS X 0212、JIS X 0213といった符号化文字集合について、どの漢字がどう入っていて、のちの規格でどう拡張して…みたいな話が延々書いてあります。
この符号化文字集合というのは、前回推定していた文字コードとはまた別の概念で、「符号化文字集合で定められた値を、実際のバイト列にどう落としこむか」を決める規格がShift_JIS、EUC-JP、ISO-2022-JP(JIS)といった「符号化方式」です。
これについてももちろん詳しく書かれています。これらの「符号化方式」は、同じ番号(JIS区点番号)を違うバイト列に変換しているだけなので、これらの間では(ほぼ)機械的に変換を行うことができるわけですね(jcode.pl、めっちゃ懐かしいです)。
ちなみにUnicodeはこれらの規格とはあんまり関係なく、それぞれの文字について、別の番号(Unicodeコードポイント)が決められているため、Shift_JISなどの方式と相互変換しようとすると、絶対に文字と文字の対応テーブルが必要になってきます。これに関してももちろん、結構細かく書いてあります。
そんな感じで詳しく文字コードについて書いてるのですけど、はっきりいって、もー複雑なんですよ!これが!!
結構集中して読んでたのですが、それでももう全然覚えてないです…。Shift_JISにしても、後々追加した漢字が使えるようになったShift_JIS-2004っていう別規格があって、どうたらこうたら…なんかもう訳わからないです^ρ^
JIS X 0208やJIS X 0213も、こっちの規格とこっちの規格で文字がかぶってるだの、新しい規格で追加したせいでShift_JISにMicrosoftが独自に追加した機種依存と被ってしまっただの…。
UnicodeとJIS X系で変換するときに、JIS X->Unicode->JIS Xってやったら元に戻るようにトリッキーな救済措置をしたら、今度はそれが仇になって、他の国の漢字と整合性が保てなくて、違う言語で同じUnicodeでの漢字がスワップしてしまったり…(”器“と”器“問題)
もう文字コードを自力で扱ったりしないよ(世界丸見え風)と固く決心させてくれるだけでも、十二分に良書なのではないか!と思います!(割りと真剣な目で
■別の視点から読んでみる:自分が拡張しなきゃいけなくなったら、どうする?
さて、この本で文字コードの複雑さに頭を悩ませるのも一興ですが、また違った楽しみ方があります。それは、自分が文字コードの開発者になったら、どう拡張したかな?というのを、色々考えてみるという楽しさです。それこそプログラマなら、一度は考えてみるべき!です!
最初期の文字コ-ドは、もちろん、ASCIIに代表される英語だけの文字コ-ド。符号化文字集合と符号化方式のようなレイヤーに別れていない、素朴な仕様です。1960年代に生まれました。
しかし、英語のアルファベットだけですから、ヨ-ロッパの国々のàみたいな別種の文字を扱うことができませんし、$記号はあるのに、自分の国の通貨記号がないのも不便です。そして、考えなければならないのは、この時代のコンピュ-タは本当にスペックが今に比べると低かった、ということ。できる限り、ASCIIで使っている7bitの範囲内で文字を表現したかったようです(その後出てくる文字コ-ドは8bitが主流だし、どうしてなのかいまいち分からないです…7bitしか扱えないことで有名なSMTPは80年代ですし…この辺の事情詳しい人居たら教えてね!)。
さて…どう拡張するべきでしょう…。ASCIIは、128種類の殆どを使いきってしまっています。制御文字も、きっと当時はみんな必要なものだったのでしょうから、自分たちの言語の文字に使うこともできそうにありません。
そのとき、標準として選ばれたのが、ISO/IEC 646です。結局、ASCIIを基本としつつ、各国ごとに文字コ-ドの規格を分離し、特殊記号に関しては自分たちで決めてね…といった感じの規格です。文字コ-ドの規格自体には、「どの文字コ-ドなのか」を区別する規格はないため、別にどの文字コ-ドなのかの情報を持っていなければなりません。そう、もうこの時点で「文字化け」という概念が発生しているのです。
■超有名な円マークとバックスラッシュ問題
たとえば、日本では、ISO 646の一種としてJIS X 0201が制定され、この規格では、ASCIIのうちの∖の代わりに¥が、˜の代わりに‾が宛がわれました。円マ-クと\…そう、この文字化け、今でも非常によく見かけますよね!私のBlogでも、たまに円マ-クがバックスラッシュになってて、「ワンコインは∖500」みたいな文章になったりしてて、なんだかよく分からない事になってます。
表示が化けるだけなら、まだ良い方です。そう思って、円マークとバックスラッシュに関しては、区別を適当にする…という感じで今まで対策がされてきました。が、この円マ-クとバックスラッシュの区別が適当な事を利用すると、クロスサイトスクリプティングできちゃったりします。これらの面倒な問題は、すべてこのISO 646の規格にまで遡っているのです…。。。
■三者三様の「半角カナ」「全角カナ」問題
さらに、このJIS X 0201では、部分的に、日本語にも対応しました。でも、当時のコンピュ-タの性能は、グラフィックもCPUもあまり高く無いため、カタカナだけです(ドット数が低いと、まるっこい文字より直線的な文字のほうが表現しやすかったんですかネ)。これも、現在でも「半角カナ」として、残っています。
この規格だけなら何の問題もありませんが、後々JIS X 0203などで拡張された際に付け加えられた「全角カナ」もあり、こちらもShift_JISやEUC-JPで使うことができます。同じ文字を二通りで表せるのは、違う文字を一通りで表してしまった円・バックスラッシュと同じく、色々と問題が発生します…。
たとえば、「半角カナ」で「アイウエオ」と書かれた文章を検索するときに、「全角カナ」で「アイウエオ」で検索してもヒットしない、ということです。これは不便ですし、掲示板のNGワ-ドを実装するときにすり抜けられてしまったり、SPAMフィルタのために文章を単語ごとに分離させるときも、同じワ-ドが違うものになってしまったり、妙な事になってしまいます。
そもそも、感覚的に、同じ文字が違うバイト列で表現されてるのは絶対変です。よくサービスの登録画面とかで「住所(全角で入力)」みたいなのがありますが、なんでそんな事しなきゃいけないんでしょう。カタカナはカタカナ。そうでしょう?
う~ん、この「半角カナ」、どうするべきだったのでしょう…。EUC-JPでは、この「半角カナ」を使うには、あるエスケープシーケンスをおいた後に続けないと、使えなくなりました。これはどういう事かというと、JIS X 0201そのままのデータを、EUC-JPとして直接読むことはできません。一旦コード変換が必要になります。今では何でもありませんが、JIS X 0201のような1バイト文字コードしか扱えない環境が多く、相互でやり取りすることが多かった時代では、結構不便だったようです。
逆に、Shift_JISはJIS X 0201をそのままにしつつ、JIS X 0201で使っていない部分に、半ば無理矢理(本来は文字が入らない、制御コードの領域も使ってしまいました)、JIS X 0213の漢字を格納しています。互換性やJIS X 0201しか扱えない環境とのデータのやり取りは簡単だったようです。が、無理やり押し込んでしまったため、例の「表示」が「侮ヲ」になる、5C問題が発生してしまいました。
電子メールで使われるISO-2022-JPは、バッサリと切り捨ててしまいました。もし半角カナの含まれたJIS X 0201や、Shift_JIS、ISO-2022-JPから変換したい場合は、すべて「全角カナ」に統一され、全角と半角の区別が失われる事になりました。
このように、三者三様の半角カナの扱い。どれが一番だと思います?現状ならISO-2022-JPのように廃止で良いと思うのですが、当時の状況を考えると、そうでもなかったようです。
ちなみに、UTF-8全盛の現在でも半角カナは生き残っていますが、Unicodeの方針としてShift_JIS->Unicode->Shift_JIS、のように変換したら、元のShift_JISと同じバイト列が得られる、ということを基本としているようで、これを満たすために「半角カナ」はまだ生き残っています。Unicodeに採用されてしまった以上、半角カナはこれからもしぶとく生き残っていくでしょう。
なお、「半角カナ」は1バイトのイメージが強いと思いますが、UnicodeやEUC-JPでは、もはやそうではありません。表示する上で半分の太さの文字にしているというだけです。
■
似たような問題が、この本にはいくつもいくつも出てきます。これらの問題も含めて、どうするべきだったのか、当時の技術の都合も想像しながら読んで「おれのかんがえたさいきょうのしよう」を考えてみると、一興かもしれません。
この週末、東大の学園祭で同人誌を出します
こんにちは!東大は今、年二回ある学園祭の一つ、駒場祭の真っ最中です。
私は東大ニコ研というサークルで生放送したり、女装をしたりしている他、土日の26/27両日に開催される東大生オンリー同人誌即売会「コミックアカデミー03」において、同人誌「エミュレータはソフトなマホウ ~ハード解析”なし”で作るファミコンエミュレータ~ 前編」を頒布いたします。ソースコードCD付属♪

プログラマなら誰でも憧れる(?)ファミコンエミュレータを、ハードウェアの直接的な解析なしに、インターネット上の情報だけで実装しよう!という本です。ハードウェアの解析をしなくても、こんなエミュレータを開発できてしまいます!ただし今回は前編までで、カートリッジ・RAM・CPUの実装だけとなっています…。ごめんなさい。
ページ数の制限もある中で、できるだけわかりやすく解説したつもり…です。解説は途中までですが、ソースコードは完全版が付属CDに収録されています。カッテネ。


渋谷の近くにお住まいの方は、ぜひ!
■場所
東京渋谷の近くにある、東京大学駒場キャンパスで駒場祭は開催されています。
この駒場キャンパスの12号館3階1233教室というところで頒布しております。
サークルとして出ているわけではなく、本部での委託販売となっています。ご注意ください。
■
当日は、私自身はこのコミックアカデミー会場か、5号館二階523教室で跳梁跋扈している予定です。よろしくお願いします。
■
なお、日曜日は東大ニコ研コミュニティで「まるきゅう」のダンスのネット中継も行います。そちらもよろしくお願いします。
統計学の力を借りて、文字化け退散! 省メモリ&実用化編
以下の記事の続きです。最終編~♪
■abstract
@nebutalabさんの追試結果を踏まえて、私もベクトルデータの解像度を下げる効果について検討しました。その上で、既存のライブラリ(Webkit/Chromeに組み込まれているライブラリ)と比較を行いました。
さらにベクトルデータをlogを用いて圧縮する方法を検討したところ、既存のライブラリと同程度にまでメモリ消費を下げることができました。
最後の仕上げとして、autotoolsを用いたライブラリとしてまとめて公開しました。
■解像度を下げてもなお特徴的なベクトルデータ
@nebutalabさんのエントリでは、二次元でなく一次元での推定テストを行った他、二次元の場合に、ベクトルデータの解像度を下げてどれくらい推定成功率が下がってしまうかのテストを行っていらっしゃいます。
なぜ、解像度をさげて正確性を犠牲にしてまで、ベクトルデータのサイズを小さくしなくてはいけないのでしょう?元のままだと、ベクトルデータが各エンコードごとに256×256=65536要素必要で、uint32(4バイト)で持っていると256KBも必要になってしまいます。Shift_JIS、EUC-JP、ISO-2022-JP、UTF8と4種類用意するとトータルで1MBです。実際に使おうとするとこのメモリ消費量の大きさがネックになってしまい、ソフトウェアの一部として組み込むには使いづらいからです。
とりあえず、私の側でも解像度を下げたデータを作って見ました。
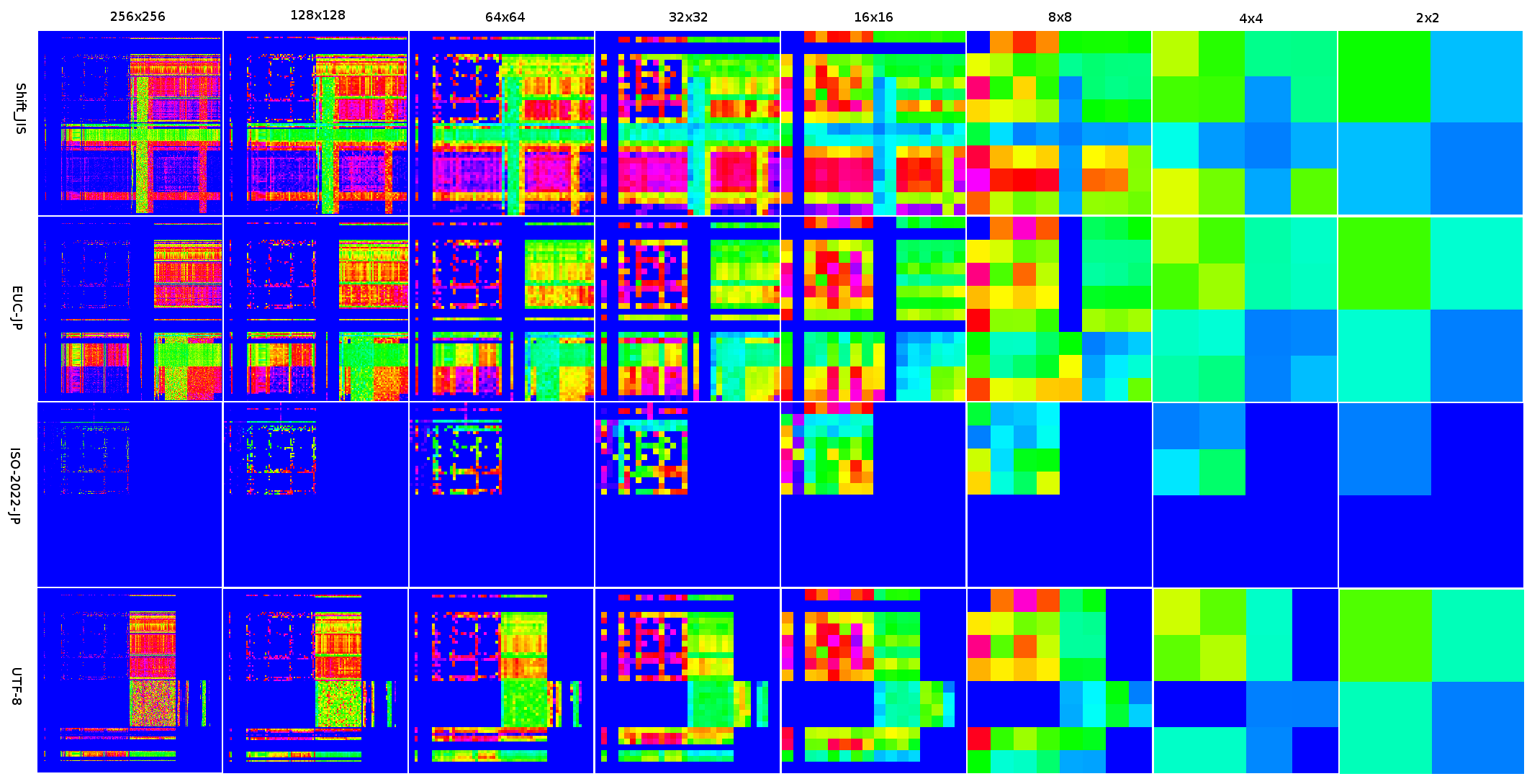
うーん、16×16までは確実に差が分かるけど、8×8くらいから怪しいかなあ、といった感じでしょうか。
■解像度を下げて実験!
今回は、@nebutalabさんの方法を参考に、ページ内でcharsetを指定してあるページのみをテスト用デ-タに使うことで、ノイズを排除しました。あと、方式は前回検討し疑似コードでの方式をベースに、charCntはどれかの文字コードのスコアが0より大きい物(判定として使える物)にしました。解像度を下げていくと、これは最初の擬似コードの方式と殆ど同じになります†1。
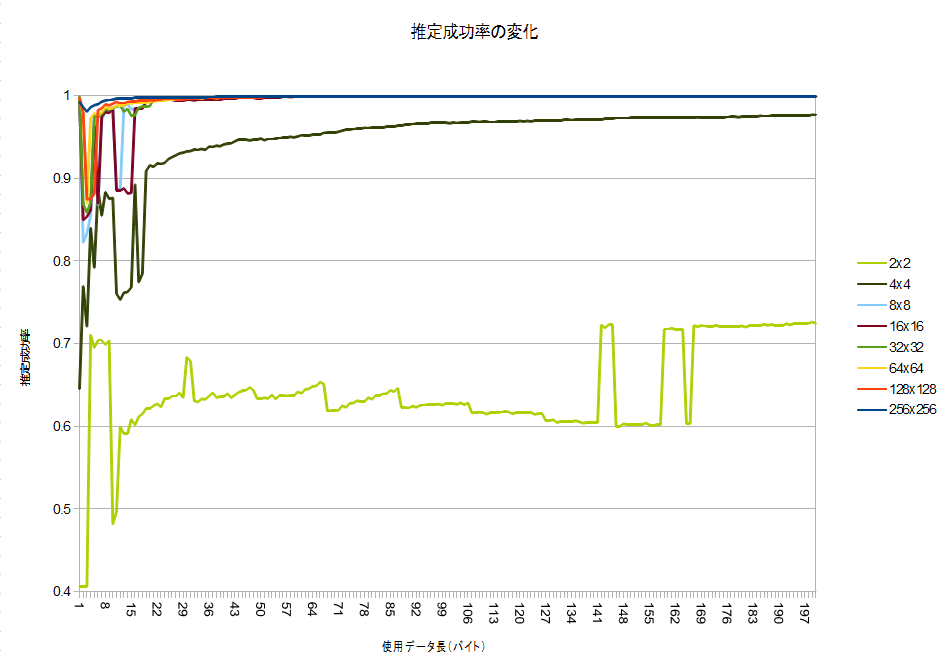
意外にも8×8では十分判定(100バイト時点で99.907%)でき、4×4で怪しくなってきて、2×2では全然だめ、という感じのようです。それでも、Random guess(25%)よりは高く、7割程度分かってしまうようです。…確率って凄いですね。
@nebutalabさんのものよりも成績が良いのは、おそらくやっぱり辞書データのサイズの差だと思われます。Wikipedia全文データはやはり広大みたいです…。
99%以上の部分についてのみのグラフがこちらです。
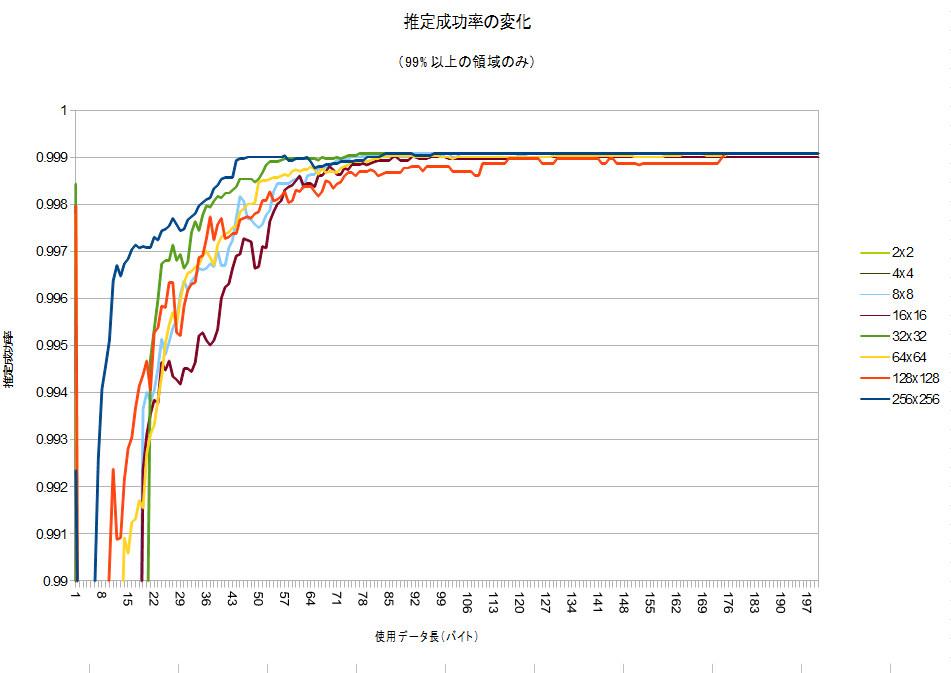
128×128で何故か収束が悪いですが、おおむね100バイト収集すれば収束するようです。ちょっと面白いのが、1バイトだけ使った方が、その後の50バイト分よりも判定率が良いこと!99.8%の精度が出ているので、案外これで十分!?かもしれません^^;
■webkitのコードと比較してみる
Chrome/Webkitで、HTTPのレスポンスヘッダやmeta要素でのcharsetと、テキストの実際のエンコードが食い違った時に推定するために使われる†2、TextResourceDecoder::detectJapaneseEncoding(const char* data, size_t len)と、性能を比較しました。コメントから、このコードは、JVIM由来だそうです。具体的に実装を見るとわかりますが、このコードもヒューリスティック†3なアルゴリズムですが、それぞれの文字コードへの深い知識を使って実装されており、今回のアルゴリズムとは対照的といえます。

どちらのコードも、最初の1バイトで高い性能を示し、いったんガクっと落ちる点など、非常によく似た性質を示しています。8×8の辞書サイズでは最初の方のデータのグラフが安定しませんが、おおむね同じような収束曲線を示しているように見えます(私の贔屓かな…)。なお、JVIMの実装はShift_JIS/EUC-JP/ISO-2022-JPの三種類しか判定できないので、そういう意味では私の勝ちです(ぇ
こちらも99%以上の部分を拡大したものがこちらです。
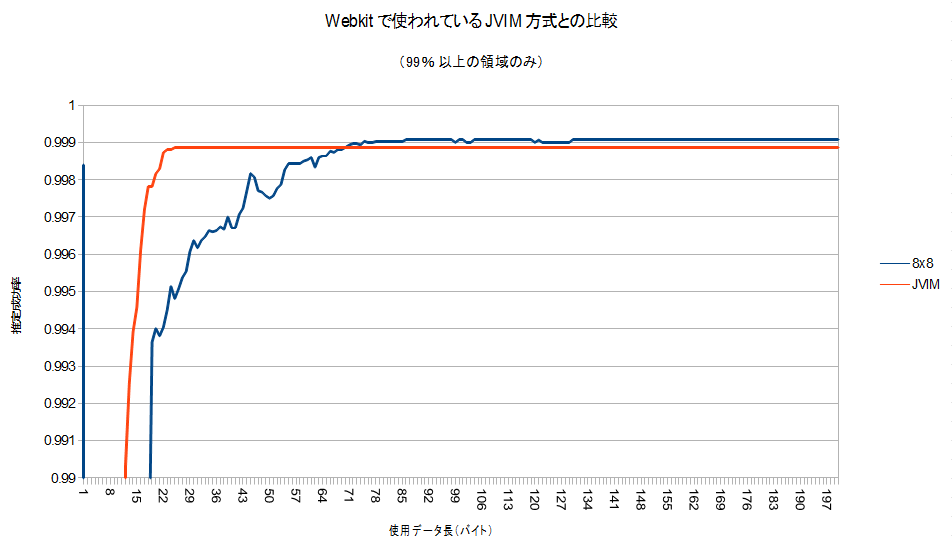
100バイト使うことが出来れば、わずかにですが、このwebkitのコードより良い性能を示しています。(合計で22876件のテストデ-タを使いました。誰か検定してください(えー))
実行時間の殆どはIOなので実行速度は問題にならないと思いますが、webkitのコードよりも確実にコード量は少なく(=省メモリ)て済んでいます。
■さらに、Logを使って圧縮しよう。
8×8にまでベクトルサイズを下げることで、ベクトルの要素を32bitのfloatで持つと、8x8x4(bytes)*4(種類のエンコード)=1024バイトにまでベクトルデータを削減することが可能ですが、これでもwebkitの実装の256バイトよりはだいぶ大きくなってしまいます。できれば、同等のメモリ消費量程度にしたいですよね。
もし、各ベクトルの要素を1バイトで表現するようにデ-タを圧縮する事ができれば、webkitの実装と同じ、256byte前後でベクトルデ-タが収まります。圧縮すると、展開のために少し速度が遅くなると思われますが、処理速度の大半はIOな上に、アルゴリズムは現状非常にシンプルなので、多少遅くなっても問題無いでしょう。
まず、データの分布を見て、特性を観察しましょう。ベクトルの要素のうち、最大のものを100%として、0~1%の間の大きさの要素が何要素あるか、1~2%の間の大きさの要素が何要素があるか…という、ヒストグラムを作ってみました。
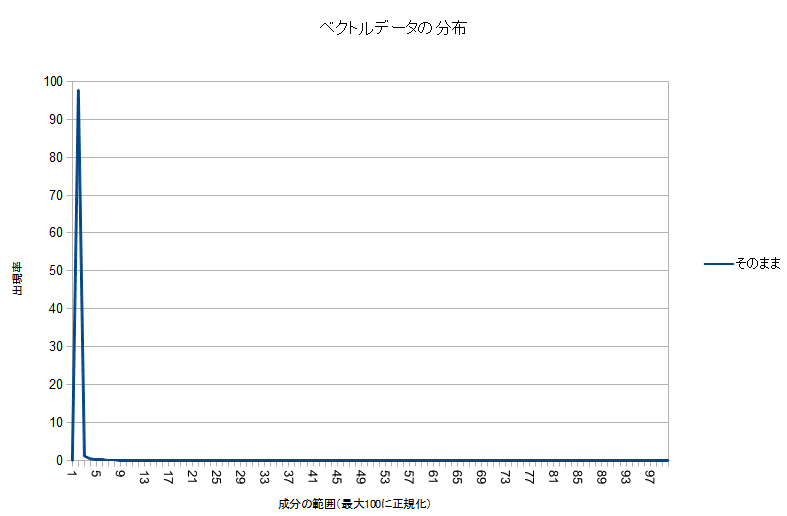
!?…どうやら、殆どのベクトル要素は、非常に小さい部分に集中しているようです。
となると、もし、ベクトルの要素の最大値を255とした場合に、各要素がどれくらいの割合か†4、でデ-タを表すことで圧縮してしまうと、圧縮後の要素が0~2の要素ばっかりのベクトルになってしまい、なんだかもったいないデ-タの使い方になってしまいます。また、解凍†5して元の要素を復元したときに、元々色々な値を持っていたはずの、値が小さい範囲の要素が、みんな同じ値に復元されてしまうことになります。
デ-タの使い方がもったいない上に、精度も悪い圧縮になってしまうので、これでは圧縮としては使えません。
では、どういう風に圧縮しましょう?小さい要素の差がつぶれて、みんな同じ値になってしまうと、もしテストデ-タを比較するときに、小さいベクトル要素ばかりが出現した場合に、みんな同じ値になってしまうので比較できなくなってしまうだろう、と思われます。逆に、非常に大きい値は、他を圧倒しているため、多少ズレてしまっても文字コ-ド別に順位を取った際の順番はあまり変わらないだろう、と考えられます。もしも圧縮するなら、小さい値をできるだけ正確に保存して、大きい値は割と目をつぶる…そんな感じが良いでしょう。
小さい要素の値をできるだけ正確に表しつつ、大きい要素はあまり正確でなくてもいい…そこで使うのが、Logです!
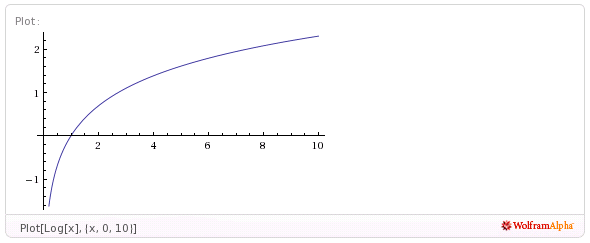
Wolfram Alpha先生に書いてもらった図です。便利ですね~。Log(x)は、xが小さい範囲では急激に増加しますが、大きくなってくると増加が緩やかになります。この関数を通すことで、値の小さい範囲の差を拡大し、大きい範囲では逆に縮小する事ができるのです。
さてさて。というわけで、ベクトルの各要素にLogを取った後に同じようにプロットした結果がこちら。

どうでしょう?だいぶ、グラフ上の色々なところに値が出現するようになりましたよね†6。Logを取った結果に、さらにLogを取るという二重対数というのもやってみましたが、これもそれなりに良い感じです。これを、最大値を255、最小値を0として表して†7、ベクトルデ-タを圧縮しました。
圧縮したデ-タを、再度元に戻した場合に、元のデ-タからどれくらい”ズレ”てしまってるかを計りました。具体的には、復元後のベクトルデ-タの各要素の合計を、元デ-タの各要素の合計で割りました。
- 何もしない(ただ最大値=255として1バイトで表す)
- Shift_JIS: 99.1276634489251%
- EUC: 98.3539033976696%
- ISO-2022-JP: 99.2222804703025%
- UTF-8: 98.8167690319413%
- 対数
- Shift_JIS: 0.392150481159483%
- EUC: 0.823989278166709%
- ISO-2022-JP: 0.419194323315878%
- UTF-8: 0.541541587104492%
- 二回対数
- Shift_JIS: 0.415910841860486%
- EUC: 0.77325609663897%
- ISO-2022-JP: 0.249110000167609%
- UTF-8: 0.574984371330254%
やっぱり何もしないのでは全然駄目でしたが、対数を使うととても正確で、二回対数にするとさらに少し改善するみたいです。どちらにしてもでも1%以下しか変わらないため、きっと良い結果が得られると考えられます。
■webkitと同程度のメモリ消費に抑えても、同じ程度の性能が出る
その結果がこちら。
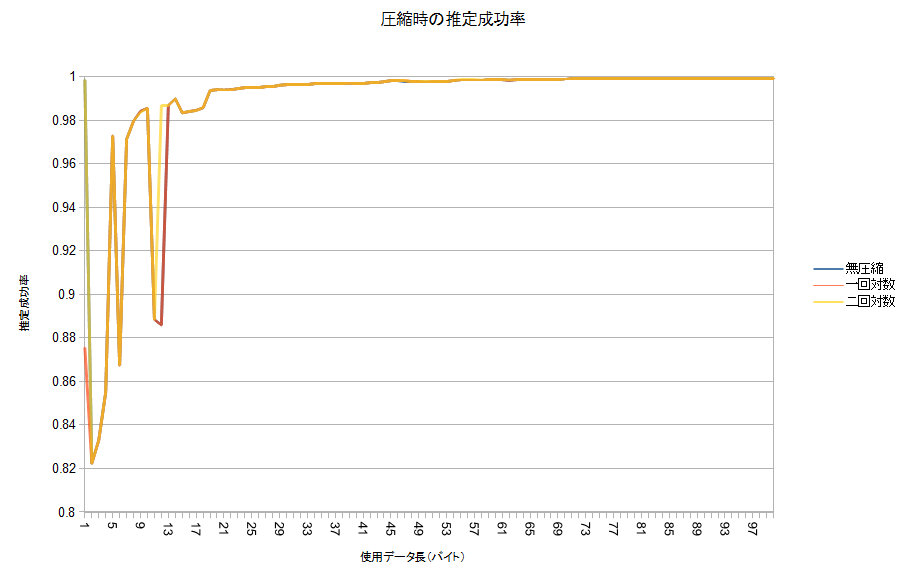
どうでしょう?一回対数の場合、1バイトだけ使ったときの推定成功率は大きく下がりましたが、元のグラフから殆ど外れないグラフが書けました。100バイト使った時の成功率は、元の結果と全く同じ。デ-タを1/4に圧縮しましたが、副作用はありませんでした。
二回対数は正直かなり重いので、実装するには一回対数を使って圧縮すると良さそうです。
■C言語のライブラリとして実装しよう!&autotoolsの使い方
さてさてさてて。すべての条件がそろいました。十分な判定率と十分なメモリ消費量、それでもシンプルなアルゴリズムを用意できました。ならば、これをライブラリにしない手は、ありませんよね!?
とてもシンプルなライブラリですから、せっかくなので、autotoolsの使い方も調べてみましょう†8。一度は自分で./configure & make & make installなパッケ-ジ作ってみたいですよね!ね!!(
とりあえず、こんな構成でコードを書きました。(完成品のソース見ながらの方が分かりやすいと思います)
- include
- csetguess.h
- src
- data.h
- data.c
- csetguess.c
include以下が/usr/includeとかに入れるためのヘッダで、
enum CSET_GUESS_CHARSETS {
UNKNWON=-1,
SJIS=0,
Shift_JIS=0,
EUC=1,
EUC_JP=1,
JIS=2,
ISO_2022_JP=2,
UTF8=3,
};
enum CSET_GUESS_CHARSETS cset_guess(const unsigned char* data, unsigned int len);
こんな感じのシグネチャが入っています。src以下はその具体的な実装です。cset_guessはcsetguess.cに入っています。
さて。これからautotoolsを使って、ビルド環境を作りましょう。autotoolsは、仕様が頻繁に変わってしまうのか、公式のドキュメントを見ても、なんかよく分かりません…。一応、作業の流れはWikipediaの図が参考になりました。Googleで検索するときも、できるだけ最新の情報を見るのをお勧めします…。
まず、トップディレクトリにMakefile.amを、こんな感じで作ります。
lib_LTLIBRARIES = libcsetguess.la libcsetguess_la_SOURCES= \ src/data.h \ src/data.c \ src/csetguess.c \ include/csetguess.h includedir=$(prefix)/include include_HEADERS=include/csetguess.h
次に、autoscanをして、configure.scanをつくり、これをconfigure.acにリネームします。
$ autoscan $ mv configure.scan configure.ac
configure.acのうち、
AC_INIT([FULL-PACKAGE-NAME], [VERSION], [BUG-REPORT-ADDRESS])
となってるところを、とりあえず自分のものに併せて変更しました。
AC_INIT([libcsetguess], [1.0], [nasda60@hotmail.com])
Wikipedaの図にそって、aclocal、autoheader、automakeします。このとき、READMEやNEWS、CHANGELOGといったファイルが無いので、automakeするときに作って貰えるように、-a -cというオプションを付けます。
$ aclocal $ autoheader $ automake -a -c configure.ac: no proper invocation of AM_INIT_AUTOMAKE was found. configure.ac: You should verify that configure.ac invokes AM_INIT_AUTOMAKE, configure.ac: that aclocal.m4 is present in the top-level directory, configure.ac: and that aclocal.m4 was recently regenerated (using aclocal). Makefile.am: installing `./INSTALL' Makefile.am: required file `./NEWS' not found Makefile.am: required file `./README' not found Makefile.am: required file `./AUTHORS' not found Makefile.am: required file `./ChangeLog' not found Makefile.am: installing `./COPYING' using GNU General Public License v3 file Makefile.am: Consider adding the COPYING file to the version control system Makefile.am: for your code, to avoid questions about which license your project uses. configure.ac:7: required file `config.h.in' not found Makefile.am:3: Libtool library used but `LIBTOOL' is undefined Makefile.am:3: The usual way to define `LIBTOOL' is to add `AC_PROG_LIBTOOL' Makefile.am:3: to `configure.ac' and run `aclocal' and `autoconf' again. Makefile.am:3: If `AC_PROG_LIBTOOL' is in `configure.ac', make sure Makefile.am:3: its definition is in aclocal's search path. Makefile.am: installing `./depcomp' /usr/share/automake-1.11/am/depend2.am: am__fastdepCC does not appear in AM_CONDITIONAL /usr/share/automake-1.11/am/depend2.am: The usual way to define `am__fastdepCC' is to add `AC_PROG_CC' /usr/share/automake-1.11/am/depend2.am: to `configure.ac' and run `aclocal' and `autoconf' again. /usr/share/automake-1.11/am/depend2.am: AMDEP does not appear in AM_CONDITIONAL /usr/share/automake-1.11/am/depend2.am: The usual way to define `AMDEP' is to add one of the compiler tests /usr/share/automake-1.11/am/depend2.am: AC_PROG_CC, AC_PROG_CXX, AC_PROG_CXX, AC_PROG_OBJC, /usr/share/automake-1.11/am/depend2.am: AM_PROG_AS, AM_PROG_GCJ, AM_PROG_UPC /usr/share/automake-1.11/am/depend2.am: to `configure.ac' and run `aclocal' and `autoconf' again.
た、たくさんエラーメッセージが出てしまいましたが、これらを地道に修正します。
@@ -2,12 +2,15 @@ # Process this file with autoconf to produce a configure script. AC_PREREQ([2.67]) AC_INIT([libcsetguess], [1.0], [nasda60@hotmail.com]) +AM_INIT_AUTOMAKE([foreign]) AC_CONFIG_SRCDIR([include/csetguess.h]) AC_CONFIG_HEADERS([config.h]) +AC_CONFIG_MACRO_DIR([m4]) # Checks for programs. AC_PROG_CC +AC_PROG_LIBTOOL # Checks for libraries.
AM_INIT_AUTOMAKEの引数がよく分からないのですが、とりあえずこれで良いみたいです(そもそもこのAM_INIT_AUTOMAKEの解説、古いのでは…?よくわかりません…)。
さて、修正したところで、再度aclocalから行って行きます。
$ aclocal $ autoheader $ automake -a -c configure.ac:13: installing `./config.guess' configure.ac:13: installing `./config.sub' configure.ac:6: installing `./install-sh' configure.ac:13: required file `./ltmain.sh' not found configure.ac:6: installing `./missing'
”configure.ac:13: required file `./ltmain.sh’ not found”するには…最初libtoolizeというのをしなければならなかったようです(Wikipediaに書いてないぞ~)
$ libtoolize libtoolize: putting auxiliary files in `.'. libtoolize: linking file `./ltmain.sh' libtoolize: putting macros in AC_CONFIG_MACRO_DIR, `m4'. libtoolize: linking file `m4/libtool.m4' libtoolize: linking file `m4/ltoptions.m4' libtoolize: linking file `m4/ltsugar.m4' libtoolize: linking file `m4/ltversion.m4' libtoolize: linking file `m4/lt~obsolete.m4' $ automake -a -c
うまく行きました。さて最後にautoconfすることで、ついにあのconfigureスクリプトが生成されます。
$ autoconf
さて、これでconfigureしましょう。
$ ./configure .... configure: creating ./config.status config.status: creating Makefile config.status: creating config.h config.status: executing depfiles commands config.status: executing libtool commands
おおお!!これで、make & make installができるようになります。
以上をまとめると、
- Makefile.amを書く
- autoscanして、configure.scanを生成し、configure.acにリネームして、編集する。
- 以下のコマンドを実行していく。
- libtoolize
- aclocal
- autoheader
- automake -a -c
- autoconf
- ./configureスクリプトができて、晴れて完成。
こんな感じです。はしょりまくりですが、とりあえずの雰囲気掴みには…なってると良いな…。とりあえず、Makefile.amとconfigure.acさえあれば全部自動生成されるので、この二つ以外はリポジトリに入れなくても大丈夫です。
■ブラウザに実装しないの?
技術的障壁が二つほど横たわっております。
- Chrome/Firefoxともに、拡張機能からページのエンコ-ド設定を変更する方法が見当たらない
- ペ-ジのテキストを、拡張機能からバイナリとして取得する方法が見つからない
後者は、Ajax的にリクエストを投げて、その結果をバイナリとして受け取る事でできそうなのですが、わざわざ再度リクエストを投げるのは計算機資源の無駄だと思います…。前者はセキュリティ的問題でしょうか…?
さらに、ブラウザ本体に組み込むというのも考えたのですが、このパソコンではどうやらメモリ不足みたいで、コンパイルに時間がかかりすぎて、デバッグや開発がどうにも不可能そうです…orz
解決方法をご存知の方がいらしたら、教えてください!
■まだちょっとやり残した気がすること
今回のJVIM由来のwebkit内のライブラリは、実はいつも使われるわけでなく、HTTPヘッダやmetaタグで指定したエンコードと実際のエンコードが食い違っている場合にのみ使われます。
そして、一切無指定だった場合はICUというUnicodeのライブラリを使ってエンコードの推定を行っています。
このICUもずいぶん高性能なライブラリのようなのですが、どうしてChrome/Webkit/Safariは文字化けが起きがちなのか、デバッグして調べたかったのです…が…。PCのメモリがどうも足りないみたいで、出来ませんでした。悲しい。
■資料
- 実験に用いたソースコードをgithubで公開します。あまり読む価値はないと思いますが、一応証拠です。
- 使ったスプレッドシート:記事では使わなかった数字とかも、とりあえず全部入ってます。これも一応証拠として。
ledyba.orgへ移転、メールアドレス変更のお知らせ
先週土曜日より、独自ドメインledyba.orgへの移転を行いました。人生初ドメインです!
ledyba.ddo.jpも、ホスティング元のDynamic DNS Doがサービスを停止するまでは、リダイレクトを提供します。(こうして”歴史的経緯”が増えていく…w)
■RSSの移行をお願いします!
RSSのアドレスも、Blog移転に伴い変更になりました。以前のアドレスからもアクセスできるようにはしていますが、できれば移行をよろしくお願いします。以下のリンクをクリックする事で、新しいフィ-ドをあなたのRSSリ-ダに登録できます。
こちらのサイトを参考にボタンを作ってみました。
■メールアドレスも変更になりました
メールアドレスも、今までpsi@science.mi.to†1を使っておりましたが、今回変更になりました。以下が新しいアドレスになります!
![]()
■経緯
今までメールアドレスpsi@science.mi.toをホストしていたサービス、”CLUB BBQ“が終了になってしまいました。そのためどこかへの移行が迫られるわけですが…正直、もうメールアドレスを変えたくありません!
そして、「そういえばledyba.ddo.jp/も無料サービスだったなあ…」と思い出しました。ddo.jpがサービスを終了すると、メ-ルアドレスと同じように使えなくなってしまうという可能性に、…やっとこさ気づいたのです!orz
メ-ルアドレスの乗り換え先に新たなサ-ビスを探すよりも、ドメイン名を取ってしまった方が良いだろうという結論に至り、ドメインを移行しました。
今後ともψ(プサイ)の興味関心空間をよろしくお願いします♪
- †1: もう使えなくなるから、SPAM対策とか一切考えずに書いちゃえ!w
統計学の力を借りて、文字化け退散! 解決&高速化編
前回までのあらすじ。
- 文字化けをどうにかしたい。
- それぞれのエンコードは、バイトとバイトのつながりに特徴がある。(数バイトで一文字表すから)
- これを、ベクトルに見立てて、それぞれの「角度」を調べて、一番近いので分類してみた。
- ある場合†1について、エンコードに含まれるASCII部分が邪魔をして推定成功率がいまいち←イマココ!
■単純に除いてみる だけ!
前回、RFCの全データを使って作ったASCIIのデータがありました。これがASCIIの使われている領域ですから、これを判断に使わなきゃ良いんじゃないの?
…というわけで、ASCII部分を除外して作ってみた各エンコードの画像がこちら。(クリックすると拡大します、ぜひクリックしてみてください)
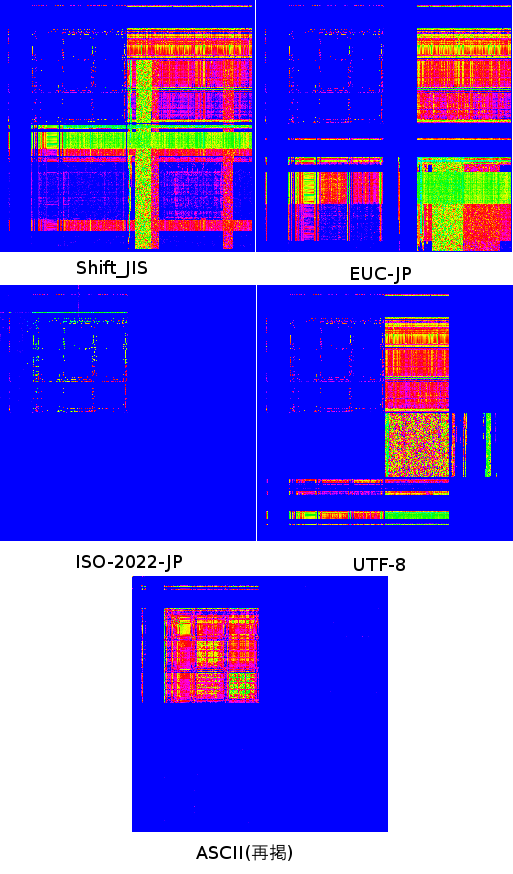
ASCIIと使用領域がかぶっているISO-2022-JP(JIS)でもちゃんと要素が残っているので、使えそうです。
かなり安直な方法†2ですが、とりあえず実験です。
■それで実験してみる
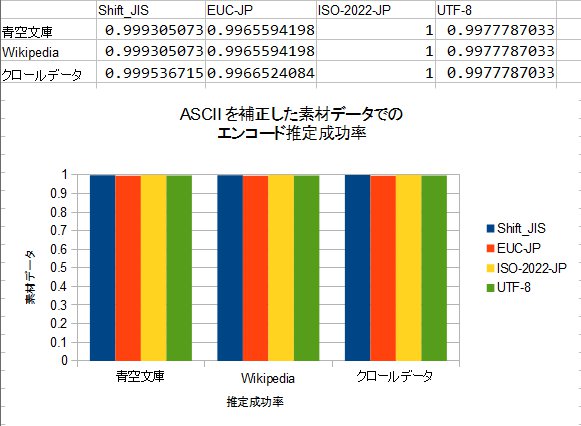
どうです!どの素材データを使っても、安定して分類出来るようになりました!ASCIIの場合、全部のエンコードに対する角度(cosθ)が0になるので、これで判断が出来ます。ただ、バックスラッシュ”∖”とチルダ”˜”の純粋ASCIIか、それぞれ円マーク”¥”とオーバーライン”‾”のJIS X 0201†3なのかは判断できません。
かなり安直な方法でしたが、効果はあるようです。
■さらにパフォーマンスを高めたい?
現状の方法では、特徴ベクトルの作成と、ベクトルの距離の比較の二つのパートから成り立っており、それぞれの計算量は
- 特徴ベクトル作成:文章の長さnに対してO(n)
- ベクトルの比較:文章にかかわらずO(1)
であり、計算量は比較的少なくて済みます(ただし計算量理論的な意味で)。
というのも、ベクトルの比較はO(1)ですが定数項が大きい(65536回のかけ算計算)です。ASCIIを除外し、更にすべてのエンコードで0になっているところを除外したところ、43394つの座標軸†4(約66%)に減らせましたが、それでも多いと言わざるを得ません。
■ファイルの長さはどれくらい必要なの?
ベクトル比較のO(1)は難しそうなのでとりあえず放置して、まず特徴ベクトルの作成をどれくらいケチれるか実験してみましょう。直感的に考えて、特徴ベクトル作成に使う文字数を増やしていっても、どこかで成功率が飽和していく事が予想されます。
Wikipediaの全文のソースを素材データ†5とし、青空文庫のうち、十分に長い小説2500本を使って実験を行いました。青空文庫は全文Shift_JISですが、それをiconvを使ってそれぞれのエンコードバージョンを作りました†6。
文章の1000バイト目†7から1バイト、2バイト、3バイト…100バイトと切っていって、それぞれで推定を行わせ、成功率を測定しました。

20バイト前後(つまり、日本語で言うと10文字程度)で飽和し、それ以降は十分な精度が得られるようです。青空文庫は非常に綺麗な日本語であることを考えても、100バイト(日本語で50文字前後)もサンプルを集めれば十二分でしょう。
余談として、ISO-2022-JPとUTF-8は若干グラフの立ち上がりが悪いですが、これはUTF-8が他のエンコ-ドと違い、日本語1文字を表すのに3~4バイト必要なこと、そしてISO-2022-JPはASCIIとかなり近い領域を使っていることが関係しているのかもしれません。
■日本語が50文字もあれば十二分な精度が出る→計算量を減らす工夫が可能に!
さて、この結果から、50文字程度の日本語を集めてくれば、十分推定可能だろうという事が判明しました。この結果を生かすと、65536回もかけ算をしなくてもコサイン類似度の比較が可能だと考えられます。
具体的には、コサイン類似度を次のようなフローで求める事で、O(1)かつ十分に小さい定数項の計算量でにエンコードの推定ができ、以上の実験結果と同じ結果が得られ、十分な推定精度が得られるのではないでしょうか?
■ほぼO(1)に高速化した推定フロー
まず、それぞれのエンコードのベクトル、V[SJIS]、V[EUC]、V[JIS]、V[UTF8]を用意しておきます。さらに、ベクトルの各要素を長さで割って、長さ1の単位ベクトル†8にしておいてください。
この時、Shift_JISのベクトルの、1バイト目がAで、2バイト目がBの要素にはV[SJIS][A][B]のようにアクセス出来るとします。
さらに、スコア決定のために使う変数、score[SJIS]、score[EUC]、score[JIS]、score[UTF8]、そしてサンプルを集めた数を記録する変数charCntを用意しておき、すべて0で初期化します。
- 文章を先頭から1バイトずつ見ていきます。
- 文章中に非ASCIIな文字が現れたら、ループに入ります。
- 現在のバイトと、一つ前のバイトを記録し、一つ前をX,現在をYとします。
- score[SJIS] += V[SJIS][X][Y]のように、それぞれのエンコードのscoreに、対応するベクトルの値を加えます。
- charCntに1を加えます。
- charCntが(例えば)100†9を超えたら、ループを終了します。
- 現在のバイトがASCIIなら、ループを終了します。
- charCntが100を超えていなければ、2へ戻り、再びその位置からバイトを見ていき、次の非ASCII文字に備えます。
- それぞれのscoreのうち、一番大きい値だったものが、この文章のエンコードと推定されます。
ミソは、まず素材データのベクトルの長さを1に揃える†10こと、さらに、比較データのベクトルは作らず、直接内積を求めること、比較データのベクトルの長さで割らなくても、最終的な値の大小関係には影響を及ぼさない事†11です。
■擬似コード
わ、わかりづらいですね。Cっぽい疑似言語でかきます。
//例えばvector[SJIS][0x30][0x21]とすると、
//SJISのベクトルで、1バイト目が0x30で、2バイト目が0x21であるときの、ベクトルの要素が取れる
//...というようなデータを事前に作成しておき、さらにベクトルの長さは各エンコードで揃えてください。
float vector[][][];
void compare(const char* text)
{
float score[];//SJIS,EUC-JP,ISO-2022-JP,UTF8の4つの要素を用意して0で初期化。
int charCnt = 0;
for(int i=1;i<strlen(text);i++)
{
if(!isAscii(text[i])){
/* サンプルを集めるためのループ */
for(;i<strlen(text);i++,chrCnt++){
//それぞれのベクトルを足す
score[SJIS] += vector[SJIS][text[i-1]][text[i]];
score[EUC-JP] += vector[EUC-JP][text[i-1]][text[i]];
score[ISO-2022-JP] += vector[ISO-2022-JP][text[i-1]][text[i]];
score[UTF8] += vector[UTF8][text[i-1]][text[i]];
if(isAscii(text[i]){ //再びasciiが現れたら、再び非ASCII文字を探す
break;
}
if(charCnt >= 100){ //十分なサンプルを採取したら
goto judge; //推定に移る(二段ループから抜けるので、break)
}
}
}
}
judge: /* スコアからエンコードを決定する */
float maxScore = 0;
encoding trueEncoding = null;
/* 一番スコアが高いエンコードを選んでるだけ */
foreach(それぞれのエンコードEについて)
{
if(score[E] > maxScore){
trueEncoding = E;
maxScore = score[E];
}
}
print("このテキストのエンコードは"+trueEncode+"です。");
}
説明用に書いただけなので、効率はあまりよろしくありません。
■さらに精度を高めたい?
また、今回はあえて文字コードに関する知識を殆ど使っていない†12ので、これを使うことで精度が多少は上げられると考えられます。むしろ、その知識をわからなかったらこういう統計的な手法に頼るべきではないかという気もします。。
■他に使えそうな分類手法は?
■ベイズフィルタ
まず、SPAMでも使われてる、ベイズフィルタ(PDF)なんてどうでしょう?このPDFにも書いてある通り、文章から「トークン」を作り出す際に、二文字ずつに区切って使うという、まさに今回使ったのと非常に似た手法「bigram」も存在するし、スパムと違って「未知の単語」は存在しないので†13、使えるかもしれません。しかし、計算量はこちらの方が大きそうです。
■回帰分析
回帰分析なんてどうでしょうか?分類するための方法ではないので少し違いますけど、正しいエンコードの時は1、間違ったエンコードの時は0を返すような係数(このページの例だとβ)を決定して、それを使ってみると良いかもしれませんね。
この分野はあまり詳しくないので、もしも他の色々な手法とか、ページとかあったら、ぜひ教えてくださいね!
■最後に
あまりにもうまく推定できすぎてて怖いので誰か追試希望
■追記
実際に追試していただけました!@nebutalabさんありがとうございます!辞書デ-タの解像度を下げる方法は、今度の休日に試してみる予定です。
■実験資料
- データが記録された、odfファイルです。グラフの元データなどがあります。
- 実験に使用したソースコード。実験しながら突貫工事で作ったので、非常に遅いです。一応証拠。今回初めてC#使いましたが、なかなか良い感じ。Mono使えばLinuxでも安心。
■
- †1: 基準データに、Webサイト上からクロールしてきたHTMLファイルを用いた場合
- †2: だって、ASCIIでの出現頻度の情報を一切使わないという事ですから…
- †3: つまり、Shift_JISやEUC-JPで英語しか書いていないのか
- †4: 「ベクトル」に見立てたんでした。ですから、座標軸ということになります。格好つけて基底ベクトルでも良いけど。
- †5: 比較する時に、前提知識として使う側のデータ
- †6: 変換できなかった文字は無視しました。仕方ないです。。。
- †7: 最初の方には、純粋な日本語以外が混じっているので
- †8: 1でなくても同じ長さなら良いです。
- †9: 大体日本語50文字分
- †10: 1でなくても、もちろん構いません。
- †11: だからベクトルを作る必要はないのです
- †12: 折角本まで買って読んでるのに…
- †13: 原理的に65536種類しか存在しません
統計学の力を借りて、文字化け退散!
現在ではだいぶ少なくなりましたが、ネットサーフィン(死語)をしていると、たまに文字化け(これも最近は死語?)に出会いますよね。

うう、なんて書いてあるのかさっぱりわからない。。。†1 ChromeだとエンコードをShift_JISと思い込んでますが、本当はEUC-JPでした。

今回は、この文字化けを回避する、”文字コードの自動推定”をやってみました。
最近「プログラマのための文字コード技術入門」という本を読んでいます。この中では日本語圏ではおなじみの、Shift_JISとISO-2022-JP(俗に言うJIS)と、EUC-JP、そして最近圧倒的なシェアを誇るUTF-8(このBlogもUTF-8です)のそれぞれの符号化方式について、変換プログラムを書くのに十分な位に詳しく説明されています。
プログラマのための文字コード技術入門 (WEB+DB PRESS plus) (WEB+DB PRESS plusシリーズ)
posted with amazlet at 11.11.06
矢野 啓介
技術評論社
売り上げランキング: 29817
技術評論社
売り上げランキング: 29817
どの方式も、ASCIIを基本として、ASCIIでは使われていないデータ部分を使って日本語(やその他の言語)を表現しています。その使い方はそれぞれの符号化方式で異なるため、「このデータの並びはShift_JISでしか使われないはず…だから、このテキストはShift_JISだろう」みたいな感じで、文字コードの推定ができます。
たとえば、昔のYahoo!JapanはEUC-JPで書かれていた(今はUTF-8)のですが、そのとき、ページの最初のほうにこんな感じのコメントが入っていました。
<!-- 京 -->
この「京」や「美乳」をEUC-JPでエンコードしたバイト列、「0xB5 0xFE」や「0xC8 0xFE 0xC6 0xFD」は、Shift_JISにもISO-2022-JPにも、さらにUTF-8にも決して現れないデータの並びです。だから、ブラウザはこのデータの並びを見たときに、「あっ、これはEUC-JPなんだな。」ってわかる(から文字化けが発生しない)、という訳です。
でも、限界もある
このようにすれば、確かに文字化けは回避できます。でも、みんながみんなこういった気の利いた(?)コメントを入れてくれる訳ではありません(そもそもHTMLには、meta要素での文字コード指定があって、むしろ上の方法よりもこちらで明記しなければならないのですが…)。そんな時、文字化けしてしまうことがあります。
たとえば、以下のバイト列†2
完璧な牛丼
をEUC-JPでエンコードしたバイト列
B4 B0 E0 FA A4 CA B5 ED D0 A7
は、そのままShift_JISと思って読み込むと
エー瓏、ハオ槢ァ
として解釈することができます。どのバイト列もShift_JISとしても有効なバイト列だからです。
よって、このバイト列がEUC-JPの「完璧な牛丼」なのか、Shift_JISの「エー瓏、ハオ槢ァ」なのか、論理的に確定させることは絶対にできない、ということになります。これが限界です。
(なおInternetExplorerはこの文字列をShift_JIS(文字化け)、ChromeはEUC-JP(正しい)として認識しました)
最初の例も、meta要素でのエンコード指定も、気の利いたコメントも無いため、Chrome14はShift_JISと勘違いしてしまった…という典型的な例です。仕方ないねー。
統計的手法を使おう!
確かに、先ほどのバイト列は、Shift_JISでもEUC-JPでも有効なバイト列でした。
でも、ですよ?
「エー瓏、ハオ槢ァ」ってまず無いだろうな~って、感覚的にはわかりますよね。たぶん「完璧な牛丼」だろう…と。こっちも意味不明ですけど…^^;
この「”エー瓏、ハオ槢ァ”よりは”完璧な牛丼”の方が『ありそう』だよね」って感じをコンピュータに自動で判断させれば、もっと正確に文字コードが判別できるはずです。
…そんなときは…そう!統計学の力を借りましょう!†3
バイトとバイトの”つながり”を手がかりにする
じゃあ、統計的手法を使って、「ありそう」かどうかを、どうやって判定すればいいのでしょう?
日本語の文字コードは、どのコードも基本的に文字列を複数のバイトを使って(例:UTF-8だと大体3バイト、他のエンコードでは2バイト)表しています。この関係性を何とか使えないでしょうか?
そこで今回は、バイトとバイトの”つながり”を手がかりにすることを考えてみました。
つまり、
- “0x00″のつぎに”0x01″が出てくるのは*回
- “0x00″のつぎに”0x02″が出てくるのは*回
- (中略)
- “0x01″のつぎに”0x00″が出てくるのは*回
- (中略)
- “0xFF”のつぎに”0xFF”が出てくるのは*回
といったデータを全部の組み合わせ(256*256 = 65536通り)について調べ、その特徴を比べます。
画像にマッピング
そのデータを使って実際に判断させる前に、とりあえず使えそうかどうか、画像で可視化することで、調べてみましょう。今回は、Wikipediaの全文データを用いて、画像を作って見ました。
X軸が1バイト目、Y軸が2バイト目です。出現頻度で色分けしてますが、適当です。
「Shift_JIS」
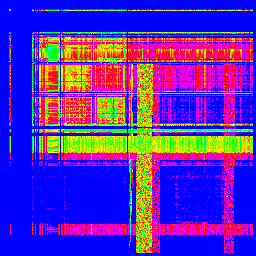
「ISO-2022-JP(俗に言うJIS)」
「EUC-JP」
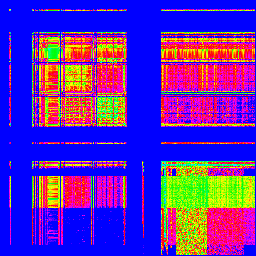
「UTF-8」
どうです?全然違いますよね! となると、これと、エンコードの分からない文章を比較すれば、その文章がどのエンコードなのか、分かるんじゃないでしょうか?
どうやって比較するの? 「コサイン類似度」
さて…人間は画像を見て一発で判断できますけれど、コンピュータはそうではありません。これをどうやってコンピュータに比較させれば良いのでしょう…うーん…画像認識…?
今回用いたのは、「コサイン類似度」と言われる方法です。順を追って説明していきます。
バイトのつながりのデータを、”ベクトル”に見立てる
この画像は二次元でマッピングされていますが、若干扱いづらいので、一列につなげて、65536通りの要素のベクトルとして扱うことにしました。プログラミングの観点から言うと、二次元配列から一次元配列に変えただけということになります。
(0, 0, ........, 1, 3, ......., 0) ←65536次元(=256x256)のベクトル
さて、ベクトルです。矢印です。二次元美少女ばっかり追いかけてるのに、三次元だと非リアなのに、65536次元なんて不安?大丈夫、ベクトルの性質は二次元の時とま~ったく同じ!ご安心ください(要素が多いので計算が人間には無理ですけど…)。
さて、このようにしてバイトのつながりをベクトルに見立てることで、
- 「推定したいファイルのエンコード」が、Shift_JIS、JIS、EUC-JP、UTF-8の中のどれなのかを調べる問題
が、
- 「推定したいファイルの”ベクトル”」と、Shift_JIS、JIS、EUC-JP、UTF-8のそれぞれの”ベクトル”を比較して、どれが一番似てるか調べる問題
に、言い換えることができました。結局、似てる矢印を探せれば良いんです。
“似ているベクトル”って、何だろう
似てるベクトル…って何でしょう??とりあえず、図をかきましょうか。二次元と全く同じように扱えるって言いましたよね。だから、普通に2次元絵で大丈夫です。
矢印には、向きと長さがあります。

一番長さが近いベクトルを似てるってするのは、どうでしょう?ほら、人間だって身長の高低で分類したりしてますし。

でも。長さって、ベクトルの各要素の二乗の和の平方根で表されるんでしたね(つまり、二次元だと長さ=√(x^2+y^2)でしたね。3次元なら√(x^2+y^2+z^2)、4次元でも、65536次元でも同じです)。
今回各要素の値は、文章内に現れたバイトの繋がりをカウントしたものでしたから、文章が長ければ(=たくさんのデータを使っていれば)、今回のベクトルの長さも長くなる…ということになります。これでは、比較には使えなさそうです。。。
というわけで、必然的に向き、つまり間の角度を比較することになります。
え…65536次元空間での角度って、何…?
2つのベクトルの間の、角度を求めるには?
まだ焦るような時間じゃない(AA略)。何度も繰り返すように、二次元と同じです。
懐かしの高校数学のおさらいです。2つのベクトルの内積というものを、
- 「成分だけ」を使ったもの
- 「長さと間の角度」を使ったもの
の、二通りを使って表せるんでした。

上で見たとおり、「長さ」も成分から求められますから、「成分だけ」を直接使って求めた内積と比較することで、cosθがわかります。(式のとおりです)
このcosθのことを、「コサイン類似度」と呼びます。角度でもいいのですけど、やっぱり65536次元での角度ってよく分からないし、空間の話でもないので別名が付いてるんだと思います。たぶん。
cos 0° = 1、cos 180° = -1ですから、この値が大きいほど、2つのベクトルの向きは似ている、ということになります。
実験結果!
さて、以上の道具立てを使って、調べてみました。Wikipediaの全文データ、青空文庫のデータ、あと各種ウェブサイトをクロールして得たデータ(たまに違うエンコードが混じっている)†4を元にして、それらとは別にクロールしたウェブサイト†5の文字コードを判定させた結果がこちらです。
ただし、クロールしたものである以上別のエンコードやASCIIのみのデータが混入しているので、95%以上で判定できれば十分な精度だと考えています。データを集めるうまい方法が思い浮かばなかったんです。。。†6
))

青空文庫の素材データは、ほぼ100%の精度でエンコードを判定してくれています!
失敗していると出た結果のところも、実際に見てみると殆どは混入しているノイズで、「むしろ正しく判定している」ものが殆どでした。これChromeに積むのってどうでしょう!?
Wikipediaは…utf-8はちょっと苦手、みたいですね。
そして、実際のウェブサイトをクロールして得た素材データは…うーん。。。一番「現場を反映している」と思っていたのですが、まさかの大苦戦…。これは、どういうことなのでしょう??
クロール素材データ使用時では、特定のウェブサイト*だけ*失敗してる?
この結果には表れていないのですけど、ログを見ていて気になったのが、クロールによって得た素材データを用いて推定した際、特定のウェブサイトにおいて*だけ*失敗していることが多いということです。SJISとUTF-8について、サイト別の判定率も出してみました。
(ニュースサイトが多いです。たくさん記事があって、エンコードが統一されてて…と選んでいくと、新聞社のページが残りました^^;)
■SJIS(クロール素材データ使用時)

房日新聞の判定成功率の低さがすさまじいです。
■UTF-8(クロール素材データ使用時)

エキサイトとCNETはうまくいくのですけど、他が…。
2つの文字コードが混じり合っている
気になるのは、どの文字コードも、英語を表すためのASCII(どれでも共通)と、日本語を表すための方式(それぞれ異なる)が入り交じっていることです。二つの要素が入り混じってしまっているため、これが問題になっているのかもしれません。
これだとどのような問題が起きるかというと、コサイン類似度の比較によって、日本語バイトデータの出現頻度の比較だけでなく、「ASCIIと日本語が、それぞれ文章内に含まれている割合」が比較要素に入ってしまう可能性があります。
例えば
- SJISの素材データはASCII多め
- EUC-JPの素材データは日本語多め
という状況で、
- ASCIIが多めのEUC-JPの比較データ
を判定させた場合、SJISに判定されやすくなる†7…などの可能性が考えられる、ということです。†8
Wikipediaや青空文庫の素材データは、あくまで「同じテキストデータ」を、「別のエンコード」で示したデータを使っているので、ASCII/日本語の割合は、すべてのエンコードにおいて同一です。そのため、比較データの日本語/ASCIIの割合の影響は、打ち消されるのではないでしょうか…?
とりあえず、ASCIIもマッピングして可視化してみる?
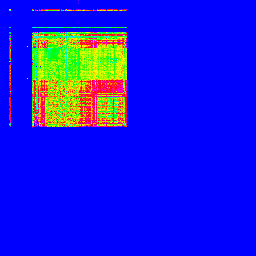
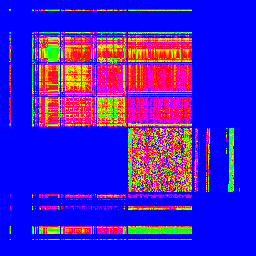
とりあえず、RFCの全データを取得し、同様に画像化してみましょう。…RFCってこんなにあったんだ…(--;
■ASCIIの出現頻度マッピング

左上の一カ所に固まってますね。これがASCIIの特徴です。これが、日本語でのデータと混ざってしまうことで、悪さをしてしまうようです…。
ASCIIと、素材データ、そして失敗した比較データを並べて眺めてみる
Webをクロールして得られた素材データと、特に失敗しているwww.bonichi.comのデータを並べた画像を作ってみました。
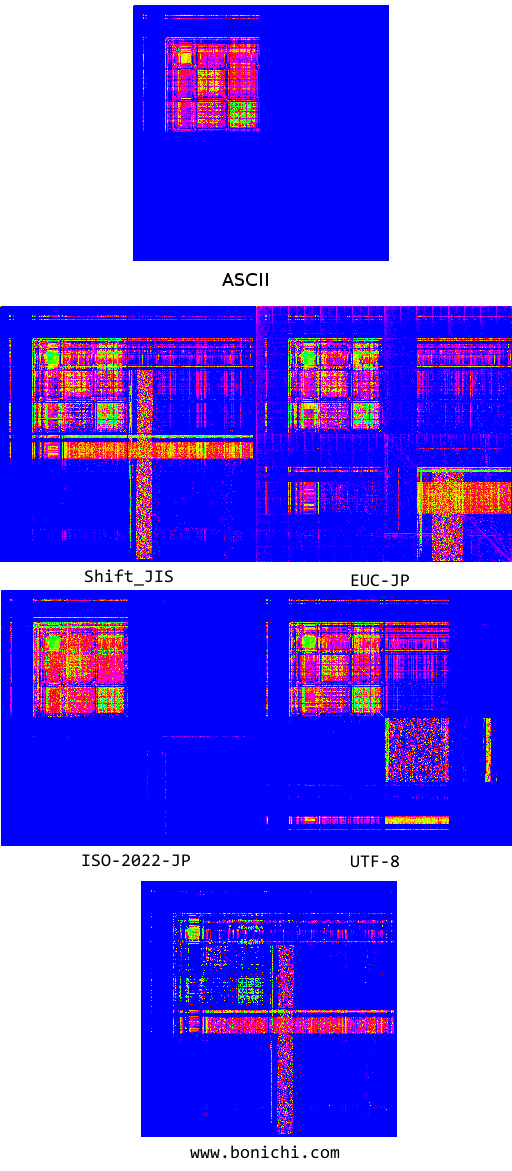
ほらほら!どの画像でも、左上には同じようなパターンが広がってますよね。どげんかせんといかん。
次回予告!
ASCIIとそれ以外の文字コードを、どのようにして混ざっている中から区別して、正しく判定することが出来るのでしょうか?
- †1: Chromeだとエンコード変更するの面倒なんですよね…
- †2: 前述の本での例をそのまま使いました。。。
- †3: 多分これは統計学の範疇だと思うんですが…どうなんでしょう^^;
- †4: 以下「素材データ」と呼びます
- †5: 以下「比較データ」と呼びます
- †6: なお、それぞれのエンコードでの、テストに用いた比較用データの数はShift_JIS:8634、EUC-JP:10754、ISO-2022-JP:3596(そもそも使ってるサイトが少なくて…^^;)、UTF-8:7203 となっております。
- †7: SJISの素材データのほうがASCIIが多めだから
- †8: さらに補足すれば、最近のウェブサイトはCMS全盛(=似たようなソースになりがち)なので、この英語と日本語の割合は同じウェブサイトなら近くなり、同じウェブサイトでばかり失敗するのかもしれません
冬コミは落ちました
今までの、ゲーム中心の共同サークルではなくて、私個人のソフトウェアネタを中心としたサークルの予定でした、が…。

ガーン!落ちてしまいました。次回にご期待ください。今まで落ちたこと無かったのに…!!ソフトウェアは倍率高いのですかね…。
■
ネットの資料だけで作るファミコンエミュレータ本を予定していました。委託とかができそうならまたお知らせします。駒場祭のコミックアカデミーはがんばってみますが、流石に間に合わないと思います…。
教えてやる!エミュレータは簡単だ!
「アフターキャンプ」というイベントでやったLT。
2017/12/06
slideshareからこちらにコピー。クラウド。それは、現代の監獄。
gccでのstatic constなクラス変数の謎挙動
今日はひたすらアセンブラを追いかけるだけのお話です。ごめんね。
■
C++では定数の定義を、defineでなく、static constな変数で行うことが推奨されてるらしいです。
// これはC++では(・A・)イクナイ!! #define VAL (1) //こっち推奨 const int VAL = 1;
基本的には、これで問題ないのですが、リンク先によると、この定数がクラス変数の場合、定義と実体の二つに分けないといけないそうです。
//ヘッダファイル側(宣言)
class Test
{
private:
protected:
public:
static const int VAL=01234;
};
//ソースファイル側(実体)
//gccでは宣言(ヘッダ)に値を書いても良いけど、VC++等の古いコンパイラだと実体に書かないといけない。
//そのためにenumハックが存在する(上記のリンク先参照)
const int Test:VAL;
ほえー、なるほど。
■
が、しかし。実際には、gccのときは、実体を書かなくても割と大丈夫みたいです。Ubuntu11.04のx86-64のgccで実験してみました(Win32のMingwでも、機械語は違いますが同じ結果でした)。
以下のソースはgithubからもDLできるよ☆彡 あ、ZIPももちろんあるよ!!
■共通のヘッダファイルはこちら。
#ifndef TEST_H
#define TEST_H
class Test
{
private:
protected:
public:
static const int VAL1=1234;
static const int VAL2=4321;
};
#endif
特に意味はないです。このTestというクラスの定数を使って、いろいろテストしてみましょう。
以下test*-*とありますが、これをmakeのビルドターゲットにすると自動でコンパイルとかしてくれます。
make test*-*
■(test1-1)実体を定義しないまま、std::coutに入れてみる。
#include "./Test.h"
#include <iostream>
int main(int argc, char** argv)
{
std::cout << "VAL: " << std::hex << Test::VAL1 << std::endl;
return 0;
}
ヘッダ上のTest::VAL1やTest::VAL2の実体を一切定義していないことに注意していください。
これをコンパイルして実行すると…
% g++ -o Test1-1.out Test1-1.cc % ./Test1-1.out VAL: 1234
どうなってるの!?と思って、アセンブラを出力させてみると…
% g++ -S -masm=intel Test1.cc ←こうすると見慣れたINTEL形式で出力してくれます % cat Test1.s
main: .LFB963: .cfi_startproc push rbp .cfi_def_cfa_offset 16 mov rbp, rsp .cfi_offset 6, -16 .cfi_def_cfa_register 6 sub rsp, 16 mov DWORD PTR [rbp-4], edi mov QWORD PTR [rbp-16], rsi mov esi, OFFSET FLAT:.LC0 mov edi, OFFSET FLAT:_ZSt4cout call _ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc ;--------------------------- mov esi, 1234 ;--------------------------- mov rdi, rax call _ZNSolsEi mov esi, OFFSET FLAT:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_ mov rdi, rax call _ZNSolsEPFRSoS_E mov eax, 0 leave .cfi_def_cfa 7, 8 ret .cfi_endproc
線で囲ったところを見てもらえばわかるとおり、インライン展開されています。ちなみに、1234という数値はこの場所以外一切定義されません。
■(test1-2)じゃ、実体を定義したらどうなるの?
定義を書き加えて
//ヘッダファイルとメイン関数の間に追加。 const int Test::VAL1;
としてアセンブラを出力してみると…。
;実体も定義される _ZN4Test4VAL1E: .long 1234 ;(略) main: .LFB963: .cfi_startproc push rbp .cfi_def_cfa_offset 16 mov rbp, rsp .cfi_offset 6, -16 .cfi_def_cfa_register 6 sub rsp, 16 mov DWORD PTR [rbp-4], edi mov QWORD PTR [rbp-16], rsi mov esi, OFFSET FLAT:.LC0 mov edi, OFFSET FLAT:_ZSt4cout call _ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc ;--------------------------- mov esi, 1234 ;--------------------------- mov rdi, rax call _ZNSolsEi mov esi, OFFSET FLAT:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_ mov rdi, rax call _ZNSolsEPFRSoS_E mov eax, 0 leave .cfi_def_cfa 7, 8 ret .cfi_endproc
Test::VALの値が埋め込みになるのは同じでしたが、それとは独立した実体も定義されました。
一切最適化オプションをつけなくても、それなりに最適化してくれるみたいです。
■(test1-3)ポインタを通す等して、実体が必要な状況をつくってみる
ポインタを通す場合、アセンブラに直接引数を書くことはできません。メモリ上に一旦置かなければなりません。
#include "./Test.h"
#include <iostream>
void outVal(const int* val)
{
std::cout << "VAL: " << *val << std::endl;
}
int main(int argc, char** argv)
{
outVal(&Test::VAL1);
return 0;
}
今度からは面倒なのでビルドターゲットでコンパイルします。†1
% make test1-3 g++ -S -masm=intel Test1-3.cc -o Test1-3.s g++ -o Test1-3.out Test1-3.cc /tmp/ccIrdzjI.o: In function `main': Test1-3.cc:(.text+0x50): undefined reference to `Test::VAL1' collect2: ld returned 1 exit status make: *** [test1-3] エラー 1
案の定実行は失敗ですね。アセンブラコードを見てみると?
;実体は定義されないけど... ;(略) main: .LFB964: .cfi_startproc push rbp .cfi_def_cfa_offset 16 mov rbp, rsp .cfi_offset 6, -16 .cfi_def_cfa_register 6 sub rsp, 16 mov DWORD PTR [rbp-4], edi mov QWORD PTR [rbp-16], rsi ;--------------------------- mov edi, OFFSET FLAT:_ZN4Test4VAL1E ;使おうとする ;--------------------------- call _Z6outValPKi mov eax, 0 leave .cfi_def_cfa 7, 8 ret .cfi_endproc
予想通りですね。
■(test1-4)でも、最適化を掛けると…。
でもしかし。同じソースのまま、-O3とかを付けて最適化を掛けると、実行可能です。
make test1-4 g++ -S -masm=intel Test1-3.cc -o Test1-4.s -O3 ;ソースは上と同じTest1-3.cc g++ -o Test1-4.out Test1-3.cc -O3 ./Test1-4.out VAL: 1234
main: .LFB1004: .cfi_startproc push rbp .cfi_def_cfa_offset 16 mov edx, 5 mov esi, OFFSET FLAT:.LC0 ;std::coutへの出力を行う別の関数(outVal)があったのに、インライン展開されてる。 ;(展開されてない、outValの実体も別箇所で存在します。) mov edi, OFFSET FLAT:_ZSt4cout push rbx .cfi_def_cfa_offset 24 sub rsp, 8 .cfi_def_cfa_offset 32 .cfi_offset 3, -24 .cfi_offset 6, -16 call _ZSt16__ostream_insertIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_PKS3_l ;---------------------------------- mov esi, 1234 ;ハードコーディング。 ;---------------------------------- mov edi, OFFSET FLAT:_ZSt4cout call _ZNSolsEi mov rbx, rax mov rax, QWORD PTR [rax] mov rax, QWORD PTR [rax-24] mov rbp, QWORD PTR [rbx+240+rax] test rbp, rbp je .L11 cmp BYTE PTR [rbp+56], 0 je .L9 movzx eax, BYTE PTR [rbp+67]
■じゃポインタにしないなら良いんだね良かった良かった
ポインタとして使えないのはdefineでも一緒ですし、だったら同じ条件ですねやったー。
…と言いたいところだが、(大佐風)微妙にこったことをすると必ず実体の定義が要らなくなるとは限りません。
■(test2-1)三項演算子の結果に使う
三項演算子を使って、フラグによって定数を振り分けたい!ありそうなシチュエーションです。
#include "./Test.h"
#include <iostream>
int main(int argc, char** argv)
{
int val = argc > 1 ? Test::VAL1 : Test::VAL2;
std::cout << "VAL: " << val << std::endl;
return 0;
}
これを最適化なしでコンパイルすると…
% make test2-1 g++ -S -masm=intel Test2.cc -o Test2-1.s g++ -o Test2-1.out Test2.cc /tmp/cc87c0Ta.o: In function `main': Test2.cc:(.text+0x17): undefined reference to `Test::VAL1' Test2.cc:(.text+0x1f): undefined reference to `Test::VAL2' collect2: ld returned 1 exit status make: *** [test2-1] エラー 1
なんと。駄目でした。アセンブラを読んでみると、
;もちろん実体は定義されてない。 main: .LFB963: .cfi_startproc push rbp .cfi_def_cfa_offset 16 mov rbp, rsp .cfi_offset 6, -16 .cfi_def_cfa_register 6 sub rsp, 32 mov DWORD PTR [rbp-20], edi mov QWORD PTR [rbp-32], rsi ;---------------------------------- ここから三項演算子 cmp DWORD PTR [rbp-20], 1 jle .L2 mov eax, DWORD PTR _ZN4Test4VAL1E[rip] ;実体は無いのに jmp .L3 .L2: mov eax, DWORD PTR _ZN4Test4VAL2E[rip] ;使おうとする。 ;---------------------------------- .L3: mov DWORD PTR [rbp-4], eax mov esi, OFFSET FLAT:.LC0 mov edi, OFFSET FLAT:_ZSt4cout call _ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc mov edx, DWORD PTR [rbp-4] mov esi, edx mov rdi, rax call _ZNSolsEi mov esi, OFFSET FLAT:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_ mov rdi, rax call _ZNSolsEPFRSoS_E mov eax, 0 leave .cfi_def_cfa 7, 8 ret .cfi_endproc
■(test2-2)最適化してみる。
でも最適化をつけると…
make test2-2 g++ -S -masm=intel Test2.cc -O3 -o Test2-2.s g++ -o Test2-2.out Test2.cc -O3 ./Test2-2.out VAL: 4321
main: .LFB1003: .cfi_startproc push rbp .cfi_def_cfa_offset 16 mov eax, 4321 mov edx, 5 mov esi, OFFSET FLAT:.LC0 push rbx .cfi_def_cfa_offset 24 mov ebx, 1234 .cfi_offset 3, -24 .cfi_offset 6, -16 sub rsp, 8 .cfi_def_cfa_offset 32 cmp edi, 2 mov edi, OFFSET FLAT:_ZSt4cout ;---------------------- cmovl ebx, eax ;フラグを見て、条件にあうならeaxをebxへ。ここが三項演算子。 ;---------------------- call _ZSt16__ostream_insertIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_PKS3_l mov esi, ebx mov edi, OFFSET FLAT:_ZSt4cout call _ZNSolsEi mov rbx, rax mov rax, QWORD PTR [rax] mov rax, QWORD PTR [rax-24] mov rbp, QWORD PTR [rbx+240+rax] test rbp, rbp je .L8 cmp BYTE PTR [rbp+56], 0 je .L4 movzx eax, BYTE PTR [rbp+67]
まさかの分岐命令…なし…!?cmovlはこちら参考。
また、何度もstd::coutの関数を呼ぶのでなく、出力関数は一度だけのようです。
■(test2-3)じゃ素直にif文を使う。
じゃあ、if文で同じことをしましょう。
#include "./Test.h"
#include <iostream>
int main(int argc, char** argv)
{
int val;
if(argc > 1){
val = Test::VAL1;
}else{
val = Test::VAL2;
}
std::cout << "VAL: " << val << std::endl;
return 0;
}
% make test2-3 g++ -S -masm=intel Test2-3.cc -o Test2-3.s g++ -o Test2-3.out Test2-3.cc ./Test2-3.out VAL: 4321
むむ。成功してしまいました。アセンブラは?
main: .LFB963: .cfi_startproc push rbp .cfi_def_cfa_offset 16 mov rbp, rsp .cfi_offset 6, -16 .cfi_def_cfa_register 6 sub rsp, 32 mov DWORD PTR [rbp-20], edi mov QWORD PTR [rbp-32], rsi cmp DWORD PTR [rbp-20], 1 jle .L2 mov DWORD PTR [rbp-4], 1234 jmp .L3 .L2: mov DWORD PTR [rbp-4], 4321 .L3: mov esi, OFFSET FLAT:.LC0 mov edi, OFFSET FLAT:_ZSt4cout call _ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc mov edx, DWORD PTR [rbp-4] mov esi, edx mov rdi, rax call _ZNSolsEi mov esi, OFFSET FLAT:_ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_ mov rdi, rax call _ZNSolsEPFRSoS_E mov eax, 0 leave .cfi_def_cfa 7, 8 ret .cfi_endproc
分岐命令で割り振るまでは三項演算子と同じ。でもif文の場合はインラインで定数を書いてくれるみたいですね。
ちなみに、最適化をかけたときの結果は、三項演算子の時と殆ど同じになりました(test2-4)。
■残りのテストの概要
残りのテストの結果は上記の結果から推測できる面白くない結果だったので概要だけ。
- test3:三項演算子でも実体が書き加えてあればちゃんと動作します。そりゃそうさね。
- test4-1:テンポラリな変数に三項演算子を代入するのでなく、そのままstd::coutに突っ込むところに直接書きました。でも駄目でした。
- test4-2:4-1をコンパイルする際に最適化を掛けると、やっぱり大丈夫でした。
■
どうやら、三項演算子はif文に展開されたりするわけではなく、別扱いになっていて、最適化フラグが掛からないときは扱いが少し違う…そんな感じでしょうか。gccのソースは読んでないのでわかりませんが…。
エミュレータで実体を定義し忘れてたのになぜか動いていたのですが、三項演算子を使ったところでコンパイルエラーでした。なお、実体を定義する前にVC++でビルドしてたので、VC++も同じようにやってくれるみたいですが、最適化の結果どうなるのか、とかは確かめてないです。
■けつろん!
- ちゃんと実体書こう!
- define替わりに使うならenumハックを検討しよう!
ほんとC++は黒魔術やでぇ…いえ、仕様通り書かない私が悪いんです。でも動いちゃうのもちょっと困るよ…。
- †1: といっても、そのmakefileも私が書いたんですが^^;