現在ではだいぶ少なくなりましたが、ネットサーフィン(死語)をしていると、たまに文字化け(これも最近は死語?)に出会いますよね。

うう、なんて書いてあるのかさっぱりわからない。。。†1 ChromeだとエンコードをShift_JISと思い込んでますが、本当はEUC-JPでした。

今回は、この文字化けを回避する、”文字コードの自動推定”をやってみました。
最近「プログラマのための文字コード技術入門」という本を読んでいます。この中では日本語圏ではおなじみの、Shift_JISとISO-2022-JP(俗に言うJIS)と、EUC-JP、そして最近圧倒的なシェアを誇るUTF-8(このBlogもUTF-8です)のそれぞれの符号化方式について、変換プログラムを書くのに十分な位に詳しく説明されています。

技術評論社
売り上げランキング: 29817
どの方式も、ASCIIを基本として、ASCIIでは使われていないデータ部分を使って日本語(やその他の言語)を表現しています。その使い方はそれぞれの符号化方式で異なるため、「このデータの並びはShift_JISでしか使われないはず…だから、このテキストはShift_JISだろう」みたいな感じで、文字コードの推定ができます。
たとえば、昔のYahoo!JapanはEUC-JPで書かれていた(今はUTF-8)のですが、そのとき、ページの最初のほうにこんな感じのコメントが入っていました。
<!-- 京 -->
この「京」や「美乳」をEUC-JPでエンコードしたバイト列、「0xB5 0xFE」や「0xC8 0xFE 0xC6 0xFD」は、Shift_JISにもISO-2022-JPにも、さらにUTF-8にも決して現れないデータの並びです。だから、ブラウザはこのデータの並びを見たときに、「あっ、これはEUC-JPなんだな。」ってわかる(から文字化けが発生しない)、という訳です。
でも、限界もある
このようにすれば、確かに文字化けは回避できます。でも、みんながみんなこういった気の利いた(?)コメントを入れてくれる訳ではありません(そもそもHTMLには、meta要素での文字コード指定があって、むしろ上の方法よりもこちらで明記しなければならないのですが…)。そんな時、文字化けしてしまうことがあります。
たとえば、以下のバイト列†2
完璧な牛丼
をEUC-JPでエンコードしたバイト列
B4 B0 E0 FA A4 CA B5 ED D0 A7
は、そのままShift_JISと思って読み込むと
エー瓏、ハオ槢ァ
として解釈することができます。どのバイト列もShift_JISとしても有効なバイト列だからです。
よって、このバイト列がEUC-JPの「完璧な牛丼」なのか、Shift_JISの「エー瓏、ハオ槢ァ」なのか、論理的に確定させることは絶対にできない、ということになります。これが限界です。
(なおInternetExplorerはこの文字列をShift_JIS(文字化け)、ChromeはEUC-JP(正しい)として認識しました)
最初の例も、meta要素でのエンコード指定も、気の利いたコメントも無いため、Chrome14はShift_JISと勘違いしてしまった…という典型的な例です。仕方ないねー。
統計的手法を使おう!
確かに、先ほどのバイト列は、Shift_JISでもEUC-JPでも有効なバイト列でした。
でも、ですよ?
「エー瓏、ハオ槢ァ」ってまず無いだろうな~って、感覚的にはわかりますよね。たぶん「完璧な牛丼」だろう…と。こっちも意味不明ですけど…^^;
この「”エー瓏、ハオ槢ァ”よりは”完璧な牛丼”の方が『ありそう』だよね」って感じをコンピュータに自動で判断させれば、もっと正確に文字コードが判別できるはずです。
…そんなときは…そう!統計学の力を借りましょう!†3
バイトとバイトの”つながり”を手がかりにする
じゃあ、統計的手法を使って、「ありそう」かどうかを、どうやって判定すればいいのでしょう?
日本語の文字コードは、どのコードも基本的に文字列を複数のバイトを使って(例:UTF-8だと大体3バイト、他のエンコードでは2バイト)表しています。この関係性を何とか使えないでしょうか?
そこで今回は、バイトとバイトの”つながり”を手がかりにすることを考えてみました。
つまり、
- “0x00″のつぎに”0x01″が出てくるのは*回
- “0x00″のつぎに”0x02″が出てくるのは*回
- (中略)
- “0x01″のつぎに”0x00″が出てくるのは*回
- (中略)
- “0xFF”のつぎに”0xFF”が出てくるのは*回
といったデータを全部の組み合わせ(256*256 = 65536通り)について調べ、その特徴を比べます。
画像にマッピング
そのデータを使って実際に判断させる前に、とりあえず使えそうかどうか、画像で可視化することで、調べてみましょう。今回は、Wikipediaの全文データを用いて、画像を作って見ました。
X軸が1バイト目、Y軸が2バイト目です。出現頻度で色分けしてますが、適当です。
「Shift_JIS」
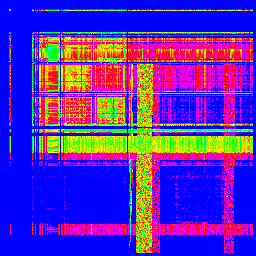
「ISO-2022-JP(俗に言うJIS)」
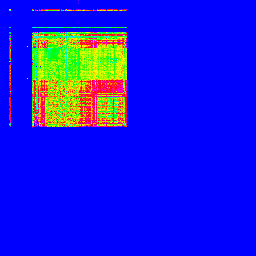
「EUC-JP」
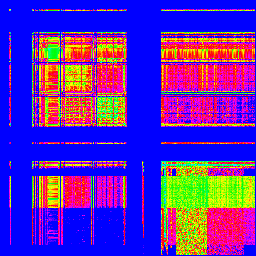
「UTF-8」
どうです?全然違いますよね! となると、これと、エンコードの分からない文章を比較すれば、その文章がどのエンコードなのか、分かるんじゃないでしょうか?
どうやって比較するの? 「コサイン類似度」
さて…人間は画像を見て一発で判断できますけれど、コンピュータはそうではありません。これをどうやってコンピュータに比較させれば良いのでしょう…うーん…画像認識…?
今回用いたのは、「コサイン類似度」と言われる方法です。順を追って説明していきます。
バイトのつながりのデータを、”ベクトル”に見立てる
この画像は二次元でマッピングされていますが、若干扱いづらいので、一列につなげて、65536通りの要素のベクトルとして扱うことにしました。プログラミングの観点から言うと、二次元配列から一次元配列に変えただけということになります。
(0, 0, ........, 1, 3, ......., 0) ←65536次元(=256x256)のベクトル
さて、ベクトルです。矢印です。二次元美少女ばっかり追いかけてるのに、三次元だと非リアなのに、65536次元なんて不安?大丈夫、ベクトルの性質は二次元の時とま~ったく同じ!ご安心ください(要素が多いので計算が人間には無理ですけど…)。
さて、このようにしてバイトのつながりをベクトルに見立てることで、
- 「推定したいファイルのエンコード」が、Shift_JIS、JIS、EUC-JP、UTF-8の中のどれなのかを調べる問題
が、
- 「推定したいファイルの”ベクトル”」と、Shift_JIS、JIS、EUC-JP、UTF-8のそれぞれの”ベクトル”を比較して、どれが一番似てるか調べる問題
に、言い換えることができました。結局、似てる矢印を探せれば良いんです。
“似ているベクトル”って、何だろう
似てるベクトル…って何でしょう??とりあえず、図をかきましょうか。二次元と全く同じように扱えるって言いましたよね。だから、普通に2次元絵で大丈夫です。
矢印には、向きと長さがあります。

一番長さが近いベクトルを似てるってするのは、どうでしょう?ほら、人間だって身長の高低で分類したりしてますし。

でも。長さって、ベクトルの各要素の二乗の和の平方根で表されるんでしたね(つまり、二次元だと長さ=√(x^2+y^2)でしたね。3次元なら√(x^2+y^2+z^2)、4次元でも、65536次元でも同じです)。
今回各要素の値は、文章内に現れたバイトの繋がりをカウントしたものでしたから、文章が長ければ(=たくさんのデータを使っていれば)、今回のベクトルの長さも長くなる…ということになります。これでは、比較には使えなさそうです。。。
というわけで、必然的に向き、つまり間の角度を比較することになります。
え…65536次元空間での角度って、何…?
2つのベクトルの間の、角度を求めるには?
まだ焦るような時間じゃない(AA略)。何度も繰り返すように、二次元と同じです。
懐かしの高校数学のおさらいです。2つのベクトルの内積というものを、
- 「成分だけ」を使ったもの
- 「長さと間の角度」を使ったもの
の、二通りを使って表せるんでした。

上で見たとおり、「長さ」も成分から求められますから、「成分だけ」を直接使って求めた内積と比較することで、cosθがわかります。(式のとおりです)
このcosθのことを、「コサイン類似度」と呼びます。角度でもいいのですけど、やっぱり65536次元での角度ってよく分からないし、空間の話でもないので別名が付いてるんだと思います。たぶん。
cos 0° = 1、cos 180° = -1ですから、この値が大きいほど、2つのベクトルの向きは似ている、ということになります。
実験結果!
さて、以上の道具立てを使って、調べてみました。Wikipediaの全文データ、青空文庫のデータ、あと各種ウェブサイトをクロールして得たデータ(たまに違うエンコードが混じっている)†4を元にして、それらとは別にクロールしたウェブサイト†5の文字コードを判定させた結果がこちらです。
ただし、クロールしたものである以上別のエンコードやASCIIのみのデータが混入しているので、95%以上で判定できれば十分な精度だと考えています。データを集めるうまい方法が思い浮かばなかったんです。。。†6
))

青空文庫の素材データは、ほぼ100%の精度でエンコードを判定してくれています!
失敗していると出た結果のところも、実際に見てみると殆どは混入しているノイズで、「むしろ正しく判定している」ものが殆どでした。これChromeに積むのってどうでしょう!?
Wikipediaは…utf-8はちょっと苦手、みたいですね。
そして、実際のウェブサイトをクロールして得た素材データは…うーん。。。一番「現場を反映している」と思っていたのですが、まさかの大苦戦…。これは、どういうことなのでしょう??
クロール素材データ使用時では、特定のウェブサイト*だけ*失敗してる?
この結果には表れていないのですけど、ログを見ていて気になったのが、クロールによって得た素材データを用いて推定した際、特定のウェブサイトにおいて*だけ*失敗していることが多いということです。SJISとUTF-8について、サイト別の判定率も出してみました。
(ニュースサイトが多いです。たくさん記事があって、エンコードが統一されてて…と選んでいくと、新聞社のページが残りました^^;)
■SJIS(クロール素材データ使用時)

房日新聞の判定成功率の低さがすさまじいです。
■UTF-8(クロール素材データ使用時)

エキサイトとCNETはうまくいくのですけど、他が…。
2つの文字コードが混じり合っている
気になるのは、どの文字コードも、英語を表すためのASCII(どれでも共通)と、日本語を表すための方式(それぞれ異なる)が入り交じっていることです。二つの要素が入り混じってしまっているため、これが問題になっているのかもしれません。
これだとどのような問題が起きるかというと、コサイン類似度の比較によって、日本語バイトデータの出現頻度の比較だけでなく、「ASCIIと日本語が、それぞれ文章内に含まれている割合」が比較要素に入ってしまう可能性があります。
例えば
- SJISの素材データはASCII多め
- EUC-JPの素材データは日本語多め
という状況で、
- ASCIIが多めのEUC-JPの比較データ
を判定させた場合、SJISに判定されやすくなる†7…などの可能性が考えられる、ということです。†8
Wikipediaや青空文庫の素材データは、あくまで「同じテキストデータ」を、「別のエンコード」で示したデータを使っているので、ASCII/日本語の割合は、すべてのエンコードにおいて同一です。そのため、比較データの日本語/ASCIIの割合の影響は、打ち消されるのではないでしょうか…?
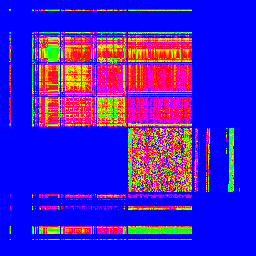
とりあえず、ASCIIもマッピングして可視化してみる?
とりあえず、RFCの全データを取得し、同様に画像化してみましょう。…RFCってこんなにあったんだ…(--;
■ASCIIの出現頻度マッピング

左上の一カ所に固まってますね。これがASCIIの特徴です。これが、日本語でのデータと混ざってしまうことで、悪さをしてしまうようです…。
ASCIIと、素材データ、そして失敗した比較データを並べて眺めてみる
Webをクロールして得られた素材データと、特に失敗しているwww.bonichi.comのデータを並べた画像を作ってみました。
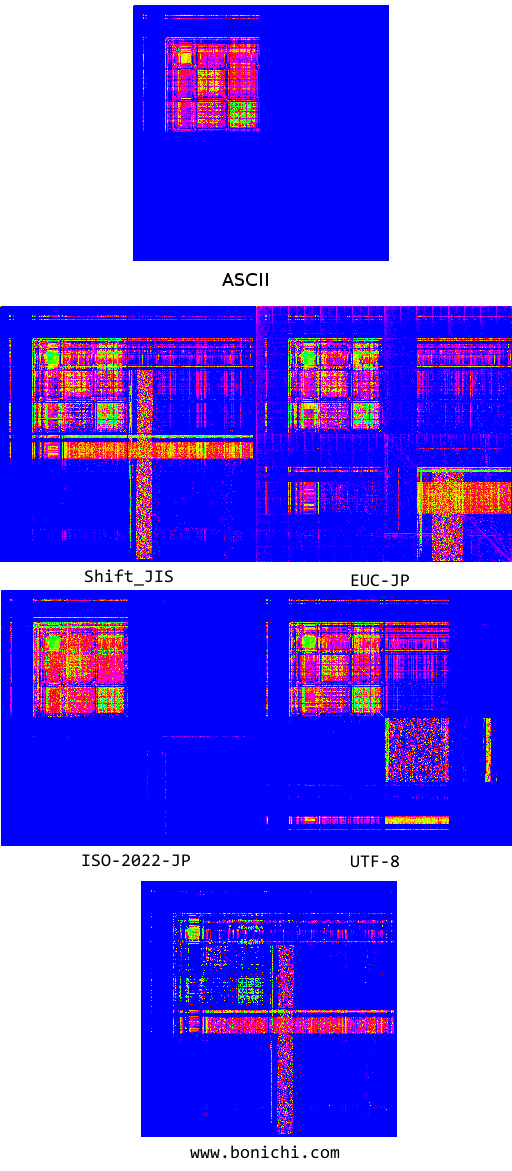
ほらほら!どの画像でも、左上には同じようなパターンが広がってますよね。どげんかせんといかん。
次回予告!
ASCIIとそれ以外の文字コードを、どのようにして混ざっている中から区別して、正しく判定することが出来るのでしょうか?
- †1: Chromeだとエンコード変更するの面倒なんですよね…
- †2: 前述の本での例をそのまま使いました。。。
- †3: 多分これは統計学の範疇だと思うんですが…どうなんでしょう^^;
- †4: 以下「素材データ」と呼びます
- †5: 以下「比較データ」と呼びます
- †6: なお、それぞれのエンコードでの、テストに用いた比較用データの数はShift_JIS:8634、EUC-JP:10754、ISO-2022-JP:3596(そもそも使ってるサイトが少なくて…^^;)、UTF-8:7203 となっております。
- †7: SJISの素材データのほうがASCIIが多めだから
- †8: さらに補足すれば、最近のウェブサイトはCMS全盛(=似たようなソースになりがち)なので、この英語と日本語の割合は同じウェブサイトなら近くなり、同じウェブサイトでばかり失敗するのかもしれません
