この記事は「[痛デバドラ] /dev/louise_love作ってみた [Linux]」の解説記事です。内部でルイズコピペを自動生成するために使った、ワードサラダの技術について解説しています。
■ワードサラダ??
みなさんはワードサラダってご存知でしょうか。サンプルとしてこのBlogを上げておきます。なんだか、日本語が変じゃありませんか?ところどころ読めるけど、なんだか変なような…。
着目すべきは、「核抑止力」を「強化」するという表現である。。
これについては核武装大腸がんの予防論を参照。。
核武装大腸がん???なんじゃそら。
こういった、ぱっと見日本語に見えるんだけど、ちゃんと読むと意味不明、という文章を「ワードサラダ」と呼びます。スパマーがプログラムで自動生成して、スパム広告用のBlogに利用しているみたいです。
さて、こんな文章どうやれば作れるんでしょう?ワードサラダの作り方を書いてあるサイトは結構あるんですが、ちゃんと動くソースコードが貼ってあるサイトはなかなかないんで、実際にやってみましょう。
■実際にRubyで作ってみよう
ソースコードは「[痛デバドラ] /dev/louise_love作ってみた [Linux]」の「辞書作成ユーティリティ」の中にありますので、DLしてみてください。githubでも公開していて、Webから見るならこちらの方が便利かもしれません。
なお、利用にはYahoo!デベロッパーネットワークのアプリケーションIDが必要です(OAuthは利用しません)。取得したIDは、parser.rb冒頭の「APP_ID」にセットしてください。
■大まかな流れ
- 文章を形態素解析
- マルコフ連鎖のための辞書を作成
- 辞書に基づいて実際にマルコフ連鎖して文章を生成
■形態素解析
形態素解析とは、文章を解析して、単語にわけ、それぞれの品詞についても調べる事です。受験の時に古文で同じことを手動でさせられましたが(涙)、受験でも何でもありませんのでコンピュータに自動で解析させましょう。
形態素解析のソフトにはMeCab等のローカルのライブラリを使うのが定石みたいですが、インストールがめんどくさいので、Yahoo!の構文解析WebAPIを使おうと思います。Web経由なんであまり高速に大量のデータは処理はできませんが、まあ実験には十分でしょう。
さらに係り受け解析の結果も使うとそれっぽい日本語が作れるようですが、目的がルイズコピペの無限生成なんで、そこまでやらなくてもそれっぽい文章ができると思います。係受け解析の結果も利用するうまい文章作成ソフトができたら/あったら教えてください。
以下、実際に行なってるコードです。「libparser.rb」内にあります。
class YahooParser < Parser
API_SERVER = 'jlp.yahooapis.jp'
API_URL = '/MAService/V1/parse';
BOM_UTF8 = [0xef, 0xbb, 0xbf].pack("c3")
def initialize(api_id = APP_ID)
@data = "appid=#{api_id}&results=ma&sentence="
end
def parse(text)
http = Net::HTTP.new(API_SERVER);
resp = http.post(API_URL,@data+URI.encode("#{text}"));
if resp.code != '200'
raise "Yahoo! Japan Parser unavailable. Return Code:#{resp.code}"
end
body = resp.body;
doc = REXML::Document.new(body).elements['ResultSet/ma_result/word_list/'];
text = Text.new();
doc.elements.each('word') {|item|
surface = item.elements['surface'].text if item.elements['surface'] != nil
next if surface.empty? || surface == BOM_UTF8
reading = item.elements['reading'].text if item.elements['reading'] != nil
pos = item.elements['pos'].text if item.elements['pos'] != nil
baseform = item.elements['baseform'].text if item.elements['baseform'] != nil
text << Word.new(surface,reading,pos,baseform)
}
return text;
end
end
概ね、’net/http’を使ってAPIのURLにPOSTで文章を送り、結果(XMLで帰ってきます)を’rexml/document’で読み込んで、形態素解析の結果を得るだけです。あえて上げれば、”elements[‘ResultSet/ma_result/word_list/’]”として、DOMを操作する手間を少し省くのがコツ…?
それぞれの要素の意味は、
- surface:字面です。「桃色」だったら「桃色」
- reading:読み方です。「桃色」だったら「ももいろ」
- pos:品詞です。「桃色」だったら「名詞」
- baseform:動詞だった場合の”終止形”です。「届け」だったら「届く」。でも、今回の文章生成には使ってません。
■マルコフ連鎖のための辞書を作成
さて、以上の形態素解析は自然言語をコンピュータで扱うなら定番の処理で、ワードサラダ生成の処理はここからが本番です。”markov.rb”内にあります。
class Dic
def initialize()
@dic = Hash.new();
@dic2 = Hash.new();
@size = 0;
end
def add(text)
if @first == nil
@first = text[0]
@second = text[1]
end
#二階
for i in 0..text.size-2
word = text[i]
if @dic[word.reading] == nil
@dic[word.reading] = Array.new
end
@dic[word.reading] << text[i+1]
@size += 1;
end
#三階
for i in 0..text.size-3
word = text[i]
word2 = text[i+1]
if @dic2[word.reading] == nil
@dic2[word.reading] = Hash.new
end
if @dic2[word.reading][word2.reading] == nil
@dic2[word.reading][word2.reading] = Array.new
end
@dic2[word.reading][word2.reading] << text[i+2]
end
end
=begin
・・・
(略)
・・・
=end
end
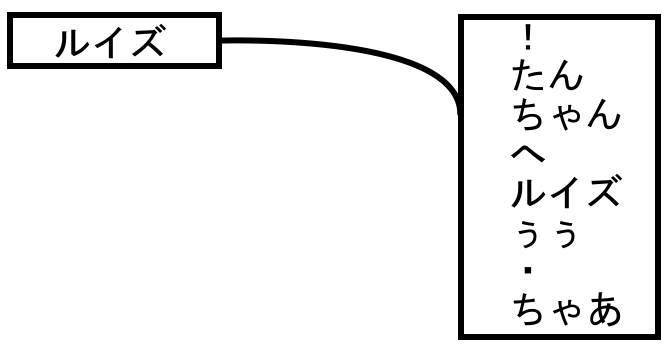
簡単にいえば、「ある単語の後にはどんな単語が来るか」というインデックスをつくっています。

こういう感じの対応表をハッシュと配列を使って記録しています。ハッシュのキーには字面ではなくよみがなを使っていて、これはなんとなくです。なお、この図とは違って同じ単語も何度でも登録していて、一応後で文章を生成したときに、「ルイズ」の後の単語の出現頻度が元の文章と同じになるように調整しています。
さらに、これだけだと文章があまりにも不安定になるので、「ルイズ/へ」→「届け」、という、ハッシュのキーが二段階になっている辞書もつくっています。これが「三階のマルコフ連鎖」と書かれているところです。
■辞書に基づいて実際にマルコフ連鎖して文章を生成
というわけで、作った辞書を使って実際に文章を生成してみましょう。同じくmarkov.rb内にあります。
class Dic
=begin
・・・
(略)
・・・
=end
def next(word = nil,word2 = nil)
if word != nil && word2 != nil
# 三階の連鎖
array = @dic2[word.reading][word2.reading];
if array == nil #辞書に入っていない場合は、二階のマルコフ連鎖を行う
array = @dic[word2.reading];
end
return array[rand(array.length)];
end
# 最初
if word == nil && word2 == nil
return @first
end
# どちらかnullでない方
left = (word == nil ? word2 : word);
# 次
if left == @first
return @second
end
# どっちかが足りない=二階の連鎖を行わざるをえない
array = @dic[left.reading];
return array[rand(array.length)];
end
end
このdic#next()に、ふたつ前の単語といっこ前の単語を渡すと、今度出力されるべき単語が返されます。
上で作った辞書からランダムに選ぶだけです。三階のための辞書は場合によっては組み合わせによって該当する辞書が空の場合があるので、その場合は二階の辞書を使います。(二階の辞書は、文章の最後の単語以外は必ず対応する単語があります)
■実際につくった文章
% ruby markov.rb <文章>
とすると実際に文章が生成されます。copipe/内にいくつか文章がすでにあります。
■ルイズコピペ
ルイズ!ルイズ!ルイズ・フランソワーズたんの桃色ブロンドの髪をクンカクンカしたいお!モフモフ!髪髪モフモフ!カリカリモフモフ…きゅんきゅい!!!!にゃあああああああ!かわいい!ルイズ!ルイズぅぅうううわぁああああああああああああああああああああああ!!
小説11巻のルイズちゃんは現実じゃないんだねっ!
この!ちきしょ!やめてやる!!
あっあんああっああんあアン様ぁあああ!!いやぁああああああああああああん!!!あぁあ!!俺の想いよルイズへ届け!!
あっあんああっああんあアン様ぁあ!!あ…小説もアニメもよく考えたら…
ルイズちゃんは現実じゃない?にゃああああ…あっあっー!あぁああああああ!!!
あぁ!クンカクンカ!
ルイズルイズぅううぁわぁああああああああああああ!!
スーハースーハー!
■吉野家
そんな事より1よ、ボケが。
150円。
お前は本当につゆだくで、それに大盛りギョク(玉子)。これ最強。
そしたらなんか人がめちゃくちゃいっぱいで座れないんです。吉野家。
よーしパパ特盛頼んじゃうぞー、とか言ってるの。もう見てらんない。
そこでまたぶち切れですよ。ボケが。
ねぎだくってなさいってこった。
素人にはお薦め出来ない。
Uの字テーブルの向かいに座った奴といつ喧嘩が始まってもおかしくない、
刺すか刺されるか、そんな雰囲気がいいんじゃねーか。おめでてーな。
お前は本当につゆだくを食いたいのかと。
そこでまたぶち切れですよ。ボケが。
吉野家ってのはな、もっと殺伐としてるべきなんだよ。ボケが。
得意げな顔して何が、つゆだくって言いたいだけ
ステーキを食べたくなったのでステーキの話を書きますが、とある日僕が気づいたのです!
やっぱりそうだ、確信した!僕の好きな食べ物は、ステーキより高いステーキソースさえあれば、そもそも本体は肉でステーキ。ちょっと新ワードですが。
それ以来、ステーキソースをかけて食べるのでは!?
ってことで、食べる!うわーこれもうまい!!
やっぱりそうだ、確信した!僕の好きな食べ物は、ステーキより高いステーキソースをかけて食べるのでは!?
と、盛り上がったところで本題に行きます。
結果から言えば牛となんら変わりませんでしたYO!
ということで、食べる!うわーこれもうまい!!
という点です。
それ以来、ステーキソースでステーキを食べておりました。
しかし!ようやく今日気づいたのです!
と、
割とサクサク読めて、でも意味がさっぱり分からない感覚は再現できましたかね?そういえば、難しい本読んだ時とかもそんな気分になるよね…。
はっ!哲学の論文をこれに掛けたら誰も分からないのでは!?