前回までのあらすじ。
- 文字化けをどうにかしたい。
- それぞれのエンコードは、バイトとバイトのつながりに特徴がある。(数バイトで一文字表すから)
- これを、ベクトルに見立てて、それぞれの「角度」を調べて、一番近いので分類してみた。
- ある場合†1について、エンコードに含まれるASCII部分が邪魔をして推定成功率がいまいち←イマココ!
■単純に除いてみる だけ!
前回、RFCの全データを使って作ったASCIIのデータがありました。これがASCIIの使われている領域ですから、これを判断に使わなきゃ良いんじゃないの?
…というわけで、ASCII部分を除外して作ってみた各エンコードの画像がこちら。(クリックすると拡大します、ぜひクリックしてみてください)
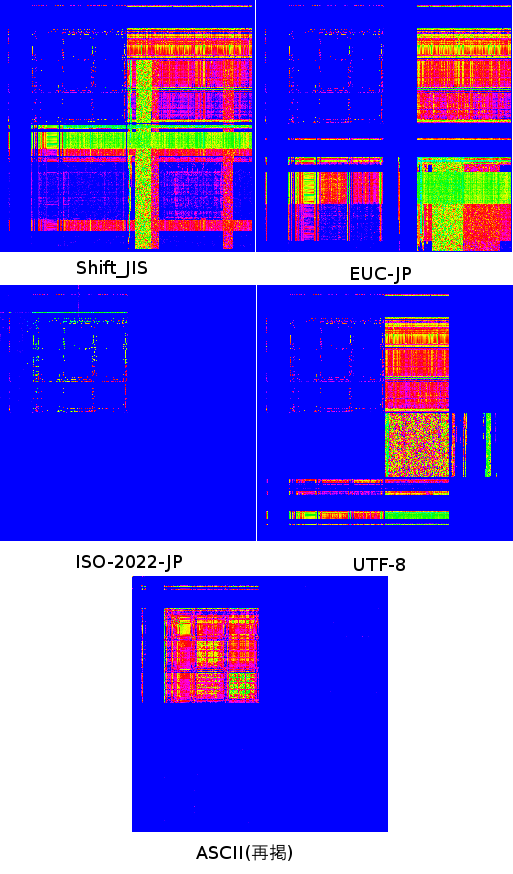
ASCIIと使用領域がかぶっているISO-2022-JP(JIS)でもちゃんと要素が残っているので、使えそうです。
かなり安直な方法†2ですが、とりあえず実験です。
■それで実験してみる
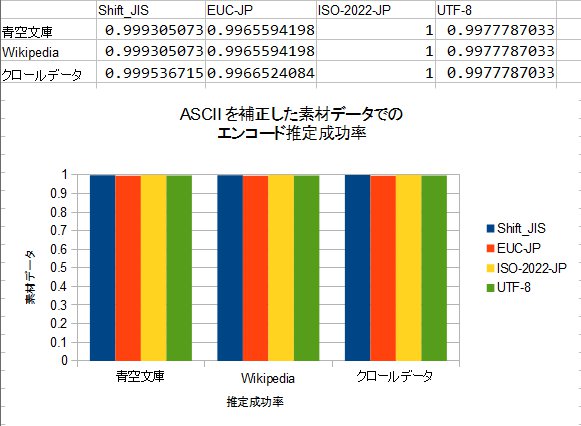
どうです!どの素材データを使っても、安定して分類出来るようになりました!ASCIIの場合、全部のエンコードに対する角度(cosθ)が0になるので、これで判断が出来ます。ただ、バックスラッシュ”∖”とチルダ”˜”の純粋ASCIIか、それぞれ円マーク”¥”とオーバーライン”‾”のJIS X 0201†3なのかは判断できません。
かなり安直な方法でしたが、効果はあるようです。
■さらにパフォーマンスを高めたい?
現状の方法では、特徴ベクトルの作成と、ベクトルの距離の比較の二つのパートから成り立っており、それぞれの計算量は
- 特徴ベクトル作成:文章の長さnに対してO(n)
- ベクトルの比較:文章にかかわらずO(1)
であり、計算量は比較的少なくて済みます(ただし計算量理論的な意味で)。
というのも、ベクトルの比較はO(1)ですが定数項が大きい(65536回のかけ算計算)です。ASCIIを除外し、更にすべてのエンコードで0になっているところを除外したところ、43394つの座標軸†4(約66%)に減らせましたが、それでも多いと言わざるを得ません。
■ファイルの長さはどれくらい必要なの?
ベクトル比較のO(1)は難しそうなのでとりあえず放置して、まず特徴ベクトルの作成をどれくらいケチれるか実験してみましょう。直感的に考えて、特徴ベクトル作成に使う文字数を増やしていっても、どこかで成功率が飽和していく事が予想されます。
Wikipediaの全文のソースを素材データ†5とし、青空文庫のうち、十分に長い小説2500本を使って実験を行いました。青空文庫は全文Shift_JISですが、それをiconvを使ってそれぞれのエンコードバージョンを作りました†6。
文章の1000バイト目†7から1バイト、2バイト、3バイト…100バイトと切っていって、それぞれで推定を行わせ、成功率を測定しました。

20バイト前後(つまり、日本語で言うと10文字程度)で飽和し、それ以降は十分な精度が得られるようです。青空文庫は非常に綺麗な日本語であることを考えても、100バイト(日本語で50文字前後)もサンプルを集めれば十二分でしょう。
余談として、ISO-2022-JPとUTF-8は若干グラフの立ち上がりが悪いですが、これはUTF-8が他のエンコ-ドと違い、日本語1文字を表すのに3~4バイト必要なこと、そしてISO-2022-JPはASCIIとかなり近い領域を使っていることが関係しているのかもしれません。
■日本語が50文字もあれば十二分な精度が出る→計算量を減らす工夫が可能に!
さて、この結果から、50文字程度の日本語を集めてくれば、十分推定可能だろうという事が判明しました。この結果を生かすと、65536回もかけ算をしなくてもコサイン類似度の比較が可能だと考えられます。
具体的には、コサイン類似度を次のようなフローで求める事で、O(1)かつ十分に小さい定数項の計算量でにエンコードの推定ができ、以上の実験結果と同じ結果が得られ、十分な推定精度が得られるのではないでしょうか?
■ほぼO(1)に高速化した推定フロー
まず、それぞれのエンコードのベクトル、V[SJIS]、V[EUC]、V[JIS]、V[UTF8]を用意しておきます。さらに、ベクトルの各要素を長さで割って、長さ1の単位ベクトル†8にしておいてください。
この時、Shift_JISのベクトルの、1バイト目がAで、2バイト目がBの要素にはV[SJIS][A][B]のようにアクセス出来るとします。
さらに、スコア決定のために使う変数、score[SJIS]、score[EUC]、score[JIS]、score[UTF8]、そしてサンプルを集めた数を記録する変数charCntを用意しておき、すべて0で初期化します。
- 文章を先頭から1バイトずつ見ていきます。
- 文章中に非ASCIIな文字が現れたら、ループに入ります。
- 現在のバイトと、一つ前のバイトを記録し、一つ前をX,現在をYとします。
- score[SJIS] += V[SJIS][X][Y]のように、それぞれのエンコードのscoreに、対応するベクトルの値を加えます。
- charCntに1を加えます。
- charCntが(例えば)100†9を超えたら、ループを終了します。
- 現在のバイトがASCIIなら、ループを終了します。
- charCntが100を超えていなければ、2へ戻り、再びその位置からバイトを見ていき、次の非ASCII文字に備えます。
- それぞれのscoreのうち、一番大きい値だったものが、この文章のエンコードと推定されます。
ミソは、まず素材データのベクトルの長さを1に揃える†10こと、さらに、比較データのベクトルは作らず、直接内積を求めること、比較データのベクトルの長さで割らなくても、最終的な値の大小関係には影響を及ぼさない事†11です。
■擬似コード
わ、わかりづらいですね。Cっぽい疑似言語でかきます。
//例えばvector[SJIS][0x30][0x21]とすると、
//SJISのベクトルで、1バイト目が0x30で、2バイト目が0x21であるときの、ベクトルの要素が取れる
//...というようなデータを事前に作成しておき、さらにベクトルの長さは各エンコードで揃えてください。
float vector[][][];
void compare(const char* text)
{
float score[];//SJIS,EUC-JP,ISO-2022-JP,UTF8の4つの要素を用意して0で初期化。
int charCnt = 0;
for(int i=1;i<strlen(text);i++)
{
if(!isAscii(text[i])){
/* サンプルを集めるためのループ */
for(;i<strlen(text);i++,chrCnt++){
//それぞれのベクトルを足す
score[SJIS] += vector[SJIS][text[i-1]][text[i]];
score[EUC-JP] += vector[EUC-JP][text[i-1]][text[i]];
score[ISO-2022-JP] += vector[ISO-2022-JP][text[i-1]][text[i]];
score[UTF8] += vector[UTF8][text[i-1]][text[i]];
if(isAscii(text[i]){ //再びasciiが現れたら、再び非ASCII文字を探す
break;
}
if(charCnt >= 100){ //十分なサンプルを採取したら
goto judge; //推定に移る(二段ループから抜けるので、break)
}
}
}
}
judge: /* スコアからエンコードを決定する */
float maxScore = 0;
encoding trueEncoding = null;
/* 一番スコアが高いエンコードを選んでるだけ */
foreach(それぞれのエンコードEについて)
{
if(score[E] > maxScore){
trueEncoding = E;
maxScore = score[E];
}
}
print("このテキストのエンコードは"+trueEncode+"です。");
}
説明用に書いただけなので、効率はあまりよろしくありません。
■さらに精度を高めたい?
また、今回はあえて文字コードに関する知識を殆ど使っていない†12ので、これを使うことで精度が多少は上げられると考えられます。むしろ、その知識をわからなかったらこういう統計的な手法に頼るべきではないかという気もします。。
■他に使えそうな分類手法は?
■ベイズフィルタ
まず、SPAMでも使われてる、ベイズフィルタ(PDF)なんてどうでしょう?このPDFにも書いてある通り、文章から「トークン」を作り出す際に、二文字ずつに区切って使うという、まさに今回使ったのと非常に似た手法「bigram」も存在するし、スパムと違って「未知の単語」は存在しないので†13、使えるかもしれません。しかし、計算量はこちらの方が大きそうです。
■回帰分析
回帰分析なんてどうでしょうか?分類するための方法ではないので少し違いますけど、正しいエンコードの時は1、間違ったエンコードの時は0を返すような係数(このページの例だとβ)を決定して、それを使ってみると良いかもしれませんね。
この分野はあまり詳しくないので、もしも他の色々な手法とか、ページとかあったら、ぜひ教えてくださいね!
■最後に
あまりにもうまく推定できすぎてて怖いので誰か追試希望
■追記
実際に追試していただけました!@nebutalabさんありがとうございます!辞書デ-タの解像度を下げる方法は、今度の休日に試してみる予定です。
■実験資料
- データが記録された、odfファイルです。グラフの元データなどがあります。
- 実験に使用したソースコード。実験しながら突貫工事で作ったので、非常に遅いです。一応証拠。今回初めてC#使いましたが、なかなか良い感じ。Mono使えばLinuxでも安心。
■
- †1: 基準データに、Webサイト上からクロールしてきたHTMLファイルを用いた場合
- †2: だって、ASCIIでの出現頻度の情報を一切使わないという事ですから…
- †3: つまり、Shift_JISやEUC-JPで英語しか書いていないのか
- †4: 「ベクトル」に見立てたんでした。ですから、座標軸ということになります。格好つけて基底ベクトルでも良いけど。
- †5: 比較する時に、前提知識として使う側のデータ
- †6: 変換できなかった文字は無視しました。仕方ないです。。。
- †7: 最初の方には、純粋な日本語以外が混じっているので
- †8: 1でなくても同じ長さなら良いです。
- †9: 大体日本語50文字分
- †10: 1でなくても、もちろん構いません。
- †11: だからベクトルを作る必要はないのです
- †12: 折角本まで買って読んでるのに…
- †13: 原理的に65536種類しか存在しません